Publications
Secure and scalable speech transcription for local and HPC
Software

A production-ready, local transcription workflow using OpenAI's Whisper, designed for security, scalability on HPC, and advanced quality control. It overcomes the privacy and reproducibility limitations of cloud-based services, offering a robust alternative for academic and enterprise use.

Investigating object orientation effects across 18 languages
Journal article
Mental simulation theories of language comprehension propose that people automatically create mental representations of objects mentioned in sentences. Mental representation is often measured with the sentence-picture verification task, wherein participants first read a sentence that implies the object property (i.e., shape and orientation). Participants then respond to an image of an object by indicating whether it was an object from the sentence or not. Previous studies have shown matching advantages for shape, but findings concerning object orientation have not been robust across languages. This registered report investigated the match advantage of object orientation across 18 languages in nearly 4,000 participants. The preregistered analysis revealed no compelling evidence for a match advantage for orientation across languages. Additionally, the match advantage was not predicted by mental rotation scores. In light of these findings, we discuss the implications for current theory and methodology surrounding mental simulation.

Multi-region investigation of ‘man’ as default in attitudes
Journal article
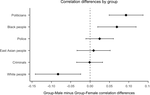
Previous research has studied the extent to which men are the default members of social groups in terms of memory, categorization, and stereotyping, but not attitudes which is critical because of attitudes’ relationship to behavior. Results from our survey (N > 5000) collected via a globally distributed laboratory network in over 40 regions demonstrated that attitudes toward Black people and politicians had a stronger relationship with attitudes toward the men rather than the women of the group. However, attitudes toward White people had a stronger relationship with attitudes toward White women than White men, whereas attitudes toward East Asian people, police officers, and criminals did not have a stronger relationship with attitudes toward either the men or women of each respective group. Regional agreement with traditional gender roles was explored as a potential moderator. These findings have implications for understanding the unique forms of prejudice women face around the world.
Starting from the very beginning: Unraveling third language (L3) development with longitudinal data from artificial language learning and related epistemology
Journal article
The burgeoning field of third language (L3) acquisition has increasingly focused on intermediate stages of language development, aiming to establish the groundwork for comprehensive models of L3 learning that encompass the entire developmental sequence. This article underscores the importance of a robust epistemological foundation, advocating for incremental knowledge building through longitudinal research. In the study presented here, we use artificial languages to investigate L3 acquisition from initial exposure with complete input control, factoring in individual differences in executive functions and history of bilingual exposure/engagement to assess the role of these variables in shaping learning trajectories and modulating cross-linguistic influence (CLI). This approach not only advances our understanding of L3 development under controlled conditions but also links L3 acquisition research to broader cognitive science inquiries.

Language and vision in conceptual processing: Multilevel analysis and statistical power
Preprint
Research has suggested that conceptual processing depends on both language-based and vision-based information. We tested this interplay at three levels of the experimental structure: individuals, words and tasks. To this end, we drew on three existing, large data sets that implemented the paradigms of semantic priming, semantic decision and lexical decision. We extended these data sets with measures of language-based and vision-based information, and analysed how the latter variables interacted with participants’ vocabulary size and gender, and also with presentation speed in the semantic priming study. We performed the analysis using mixed-effects models that included a comprehensive array of fixed effects—including covariates—and random effects. First, we found that language-based information was more important than vision-based information. Second, in the semantic priming study—whose task required distinguishing between words and nonwords—, both language-based and vision-based information were more influential when words were presented faster. Third, a ‘task-relevance advantage’ was identified in higher-vocabulary participants. Specifically, in lexical decision, higher-vocabulary participants were more sensitive to language-based information than lower-vocabulary participants. In contrast, in semantic decision, higher-vocabulary participants were more sensitive to word concreteness. Fourth, we demonstrated the influence of the analytical method on the results. These findings support the interplay between language and vision in conceptual processing, and demonstrate the influence of measurement instruments on the results. Last, we estimated the sample size required to reliably investigate various effects. We found that 300 participants were sufficient to examine the effect of language-based information contained in words, whereas more than 1,000 participants were necessary to examine the effect of vision-based information and the interactions of both former variables with vocabulary size, gender and presentation speed. In conclusion, this power analysis reveals the need to increase sample sizes when conducting research on perceptual simulation and individual differences.

Language and sensorimotor simulation in conceptual processing: Multilevel analysis and statistical power
Thesis
Multilevel analyses investigating the interplay between language-based and vision-based information in conceptual processing across semantic priming, semantic decision and lexical decision paradigms, with power analyses revealing sample size requirements for examining perceptual simulation and individual differences.

Preregistration: The interplay between linguistic and embodied systems in conceptual processing
PreprintThis preregistration outlines a study that will investigate the dynamic nature of conceptual processing by examining the interplay between linguistic distributional systems—comprising word co-occurrence and word association—and embodied systems—comprising sensorimotor and emotional information. A set of confirmatory research questions are addressed using data from the Calgary Semantic Decision project, along with additional measures for the stimuli corresponding to distributional language statistics, embodied information, and individual differences in vocabulary size.

More refined typology and design in linguistic relativity: The case of motion event encoding
Journal articleLinguistic relativity is the influence of language on other realms of cognition. For instance, the way movement is expressed in a person’s native language may influence how they perceive movement. Motion event encoding (MEE) is usually framed as a typological dichotomy. Path-in-verb languages tend to encode path information within the verb (e.g., ‘leave’), whereas manner-in-verb languages encode manner (e.g., ‘jump’). The results of MEE-based linguistic relativity experiments range from no effect to effects on verbal and nonverbal cognition. Seeking a more definitive conclusion, we propose linguistic and experimental enhancements. First, we examine state-of-the-art typology, suggesting how a recent MEE classification across twenty languages (Verkerk, 2014) may enable more powerful analyses. Second, we review procedural challenges such as the influence of verbal thought and second-guessing in experiments. To tackle these challenges, we propose distinguishing verbal and nonverbal subgroups, and having enough filler items. Finally we exemplify this in an experimental design.
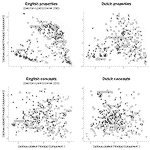
Dutch modality exclusivity norms for 336 properties and 411 concepts
Preprint
Part of the toolkit of language researchers is formed of stimuli that have been rated on various dimensions. The current study presents modality exclusivity norms for 336 properties and 411 concepts in Dutch. Forty-two respondents rated the auditory, haptic, and visual strength of these words. Mean scores were then computed, yielding acceptable reliability values. Measures of modality exclusivity and perceptual strength were also computed. Furthermore, the data includes psycholinguistic variables from other corpora, covering length (e.g., number of phonemes), frequency (e.g., contextual diversity), and distinctiveness (e.g., number of orthographic neighbours), along with concreteness and age of acquisition. To test these norms, Lynott and Connell's (2009, 2013) analyses were replicated. First, unimodal, bimodal, and tri-modal words were found. Vision was the most prevalent modality. Vision and touch were relatively related, leaving a more independent auditory modality. Properties were more strongly perceptual than concepts. Last, sound symbolism was investigated using regression, which revealed that auditory strength predicted lexical properties of the words better than the other modalities did, or else with a different direction. All the data and analysis code, including a web application, are available from https://osf.io/brkjw.

Modality switch effects emerge early and increase throughout conceptual processing: Evidence from ERPs
Conference paper
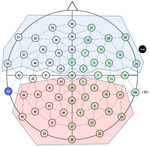
We tested whether conceptual processing is modality-specific by tracking the time course of the Conceptual Modality Switch effect. Forty-six participants verified the relation between property words and concept words. The conceptual modality of consecutive trials was manipulated in order to produce an Auditory-to-visual switch condition, a Haptic-to-visual switch condition, and a Visual-to-visual, no-switch condition. Event-Related Potentials (ERPs) were time-locked to the onset of the first word (property) in the target trials so as to measure the effect online and to avoid a within-trial confound. A switch effect was found, characterized by more negative ERP amplitudes for modality switches than no-switches. It proved significant in four typical time windows from 160 to 750 milliseconds post word onset, with greater strength in posterior brain regions, and after 350 milliseconds. These results suggest that conceptual processing may be modality-specific in certain tasks, but also that the early stage of processing is relatively amodal.

Modality switches occur early and extend late in conceptual processing: Evidence from ERPs
Thesis
Event-related potential experiment investigating conceptual modality switching, finding early-onset negativity effects (160-750 ms) that increase over time, suggesting sensory regions have a functional role in conceptual processing and supporting the compatibility of distributional and embodied processing.

Language evolution: Current status and future directions
Conference paperThe topic of language evolution is characterised by the scarcity of records, but also by a large flow of research produced within multiple subtopics and perspectives. Over the past few decades, significant advancement has been made on the geographical and temporal origins of language, while current work is rather devoted to the underpinnings of language, in brain, genes, body, and culture of humans. Much of this literature is polarized over the crucial dichotomy of nativism versus emergentism. Our state of affairs report also confirms a high degree of speculation, albeit with a decrease for modelling. To tackle the speculation and the large research flow, we propose a more impersonal kind of review, focused on the topic’s questions rather than on particular accounts. Another observation is that novel perspectives are on the rise. One of these highlights the importance of perceptual cognition, often dubbed ‘embodiment,’ in the earlier evolution of language. In following this lead, we adapted a previous experiment which had investigated the correspondence between certain perceptual features of events, and different grammatical orders arising as participants acted out those events. That design made a perfect basis for us to put in an additional variable, namely the contrast between body-based communication (gestures), and more disembodied communication (symbol matching). Albeit tentative, the results of this pilot experiment reveal a greater effect of the embodiment variable on the grammatical preferences, which we see as inviting further exploration of embodied cognition in language evolution.