Data is present: Workshops and datathons
Enhanced data presentation using reproducible documents and dashboards
Calendar
| Date | Title | Event and location | Registration |
|---|---|---|---|
| 26 Nov 2020 | Mixed-effects models in R, and a new tool for data simulation | New Tricks Seminars, Dept. Psychology, Lancaster University [online] | |
| 8 Oct 2020 | Reproducibilidad en torno a una aplicación web | Reprohack en español, LatinR Conference 2020 [online] | Link |
| 13 Aug 2020 | Open data and reproducibility: R Markdown, data dashboards and Binder v2.1 (co-led with Florencia D’Andrea) | CarpentryCon@Home, The Carpentries [online] | Link |
| 26 July 2020 | Open data and reproducibility: R Markdown, data dashboards and Binder (co-led with Eirini Zormpa) | UK Cognitive Linguistics Conference, University of Birmingham [online] | Link |
| 6 May 2020 | R Markdown | Lancaster University [online] | |
| Event cancelled | Open data and reproducibility 2.0 | SatRday Newcastle upon Tyne, Newcastle University | Link |
Background
This project offers free activities to learn and practise reproducible data presentation. Pablo Bernabeu organises these events in the context of a Software Sustainability Institute Fellowship.
Open-source software
Programming languages such as R and Python offer free, powerful resources for data processing, visualisation and analysis. Experience in these programs is highly valued in data-intensive disciplines.
Open data
Original data has become a public good in many research fields thanks to cultural and technological advances. On the internet, we can find innumerable data sets from sources such as scientific journals and repositories (e.g., OSF), local and national governments (e.g., London, UK [1, 2]), non-governmental organisations (e.g., data.world), etc. Researchers inside and outside academia nowadays share a lot of their data under attribution licences (e.g., Creative Commons, the UK Open Government Licence, etc.). This allows any external analysts to access these raw data, create (additional) visualisations and analyses, and share these. In society, making data more accessible can demonstrably benefit citizens (despite limitations).
Activities
Activities comprise free workshops and datathons.
Workshops
R is a programming language greatly equipped for the creation of reproducible documents and dashboards. Four workshops are offered that cover a suite of interrelated tools—R, R Markdown, data dashboards and Binder environments—, all underlain by reproducible workflows and open-source software.
Each workshop includes taught and practical sections. The practice provides a chance for participants to experience and address common issues with the code. The level of taught sections is largely tailored to participants; similarly, practice sections are individually adaptable by means of easier and tougher tasks. The duration is also flexible, and some of the workshops can be combined into the same session.
The RStudio interface is used in all workshops. Multi-levelled, real code examples are used. Throughout the workshops, and especially in the practice sections, individual questions will be encouraged.
Workshop 1: Introduction to R
This workshop can serve as an introduction to R or a revision. It demonstrates what can be done in R, and provides resources for individual training. Since the duration is limited, online courses are also recommended (see examples and fee waivers for full content).
- Data structures
- Packages: general-purpose examples (e.g., tidyverse) and more specific ones (e.g., for statistics or geography)
- Loading and writing data, in native and foreign formats
- Tidy format
- Wide versus long format. For most processes in R, data needs to be in a tidy, long format.
Illustration from Postma and Goedhart (2019).
- Combining data sets
- Data summaries
- Plots with
ggplot2::ggplot() - Interactive plots with
plotly::ggplotly() - Statistics
- Linear mixed-effects models (see also a review of practices)
- How functions work
- Debugging. Code errors are known as bugs. They can tiresome, but also interesting sometimes! :sweat_smile: Some tips for the first many years of experience include: reading and investigating error messages, in both source and console windows; controlling letter case and typos; closing parentheses and inverted commas; ensuring to have the necessary packages installed and loaded; following the format required by each function. To debug, break up code into subcomponents and test each of those to find out the source of the error. Once we act on that, the best outcome is seeing the code work, but sometimes different errors overlap, in which case we may see one error disappearing before another one appears. Debugging soon leads to proficient information seeking. The search process often begins on an internet search engine and extends to user communities, package documentation, tutorials, blogs… (see video explanation). Advanced debugging tools are also available.
- Vast availability of free resources on the internet, from Coursera and other MOOC sites, RStudio, University of Glasgow, Carpentries, etc.
- Community: StackOverflow, RStudio Community, Github issues (e.g., for R packages), etc. Using and contributing back.
- RStudio Cloud: a personal RStudio environment on the internet
Workshop 2: R Markdown documents
Set your input and output in stone using R Markdown. The analysis reports may be enriched with website features (HTML/CSS) and published as HTML, PDF or Word documents. Moreover, with R packages such as bookdown, bookdownplus, blogdown and flexdashboard, documents can be formatted as websites, digital papers and books and data dashboards. Other useful packages include rmarkdown, knitr, DT, kableExtra and ggplot2. Further background: presentation by Michael Frank, slides by Ed Berry.
As well as facilitating the reproducibility of analyses and results to third parties, R Markdown is helpful during the creation of a report. In particular, it reduces the chances of errors and the number of repetitive tasks. For instance, any part of the data can be inputted in the text directly from the source, rather than manually copying it (e.g., `r mean(dat[dat$location=='Havana', 'measure'])` (expand). Thus, if and when the analysis needs to be changed or updated, the report can be automatically updated at the click of a button. In another area, the captions for figures and tables can be automatised using cross-reference labels (e.g., Table \@ref(tab:mtcars)). This secures the match between the text and the captions of figures and tables, and it automatically updates the numbering whenever and wherever a new figure or table is introduced.

Image from bookdownplus package (https://bookdownplus.netlify.com/portfolio/).
Workshop 3: Introduction to data dashboards
Data dashboards are web applications used to visualise data in detail through tables and plots. They assist in explaining and accounting for our data processing and analysis. They don’t require any coding from the end user. While most dashboards and web applications present existing data, a few of them serve the purpose of creating or simulating new data (see example).
These all-reproducible dashboards are published as websites, and thus, they can include hyperlinks and downloadable files. Some of the R packages used are knitr, DT, kableExtra, reactable, ggplot2, plotly, rmarkdown, flexdashboard and shiny. The aim of this workshop is to practise creating different forms of dashboards—Flexdashboard and Shiny—the latter of which offers greater features, and to practise also with the hosting platforms fitting each type—such as personal websites, RPubs, Binder, Shinyapps and custom servers.
A great thing about dashboards is that they may be made very simple, but they can also be taken to the next level using some HTML, CSS or Javascript code (on top of the back-end code present in the R packages used), which is addressed in the next workshop.
Workshop 4: Binder environments and improving data dashboards
Binder
Binder is a tool to facilitate public access to software environments—for instance, by publishing an RStudio environment on the internet. Binder can also host Shiny apps. It is generously free for users. After looking at the nuts and bolts of a deployment, participants will be able to deploy their own Binder environments and check the result by the end of the workshop. For this purpose, it’s recommended to have data and R code ready, ideally in a GitHub repository.
Improving data dashboards
We will practise how to improve the functionality of dashboards using some HTML, CSS and Javascript code, which is the basis of websites.
<!-- Javascript function to enable a hovering tooltip -->
<script>
$(document).ready(function(){
$('[data-toggle="tooltip1"]').tooltip();
});
</script>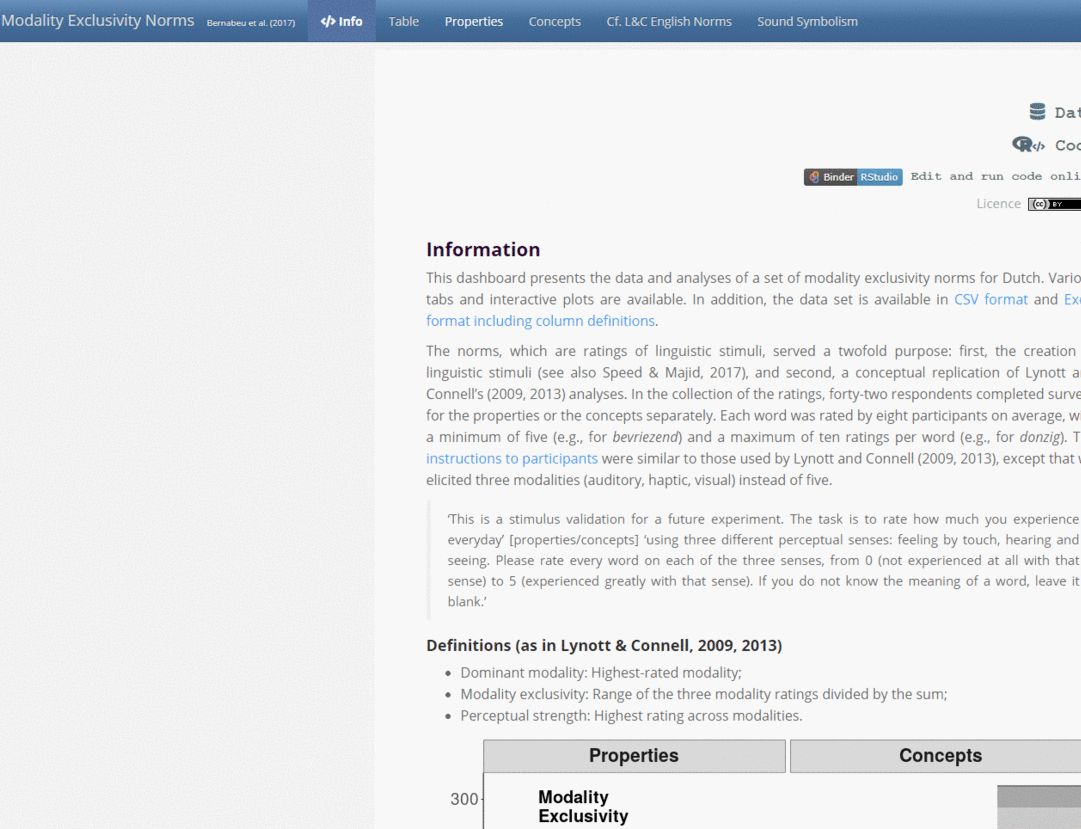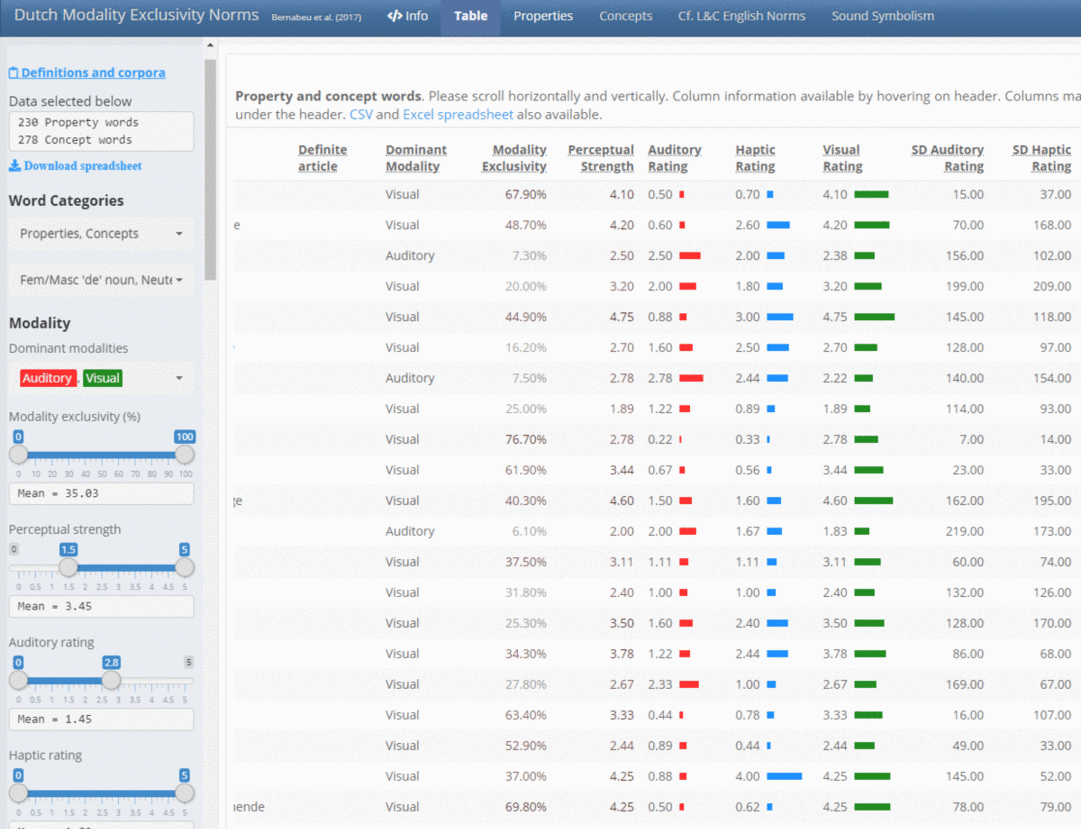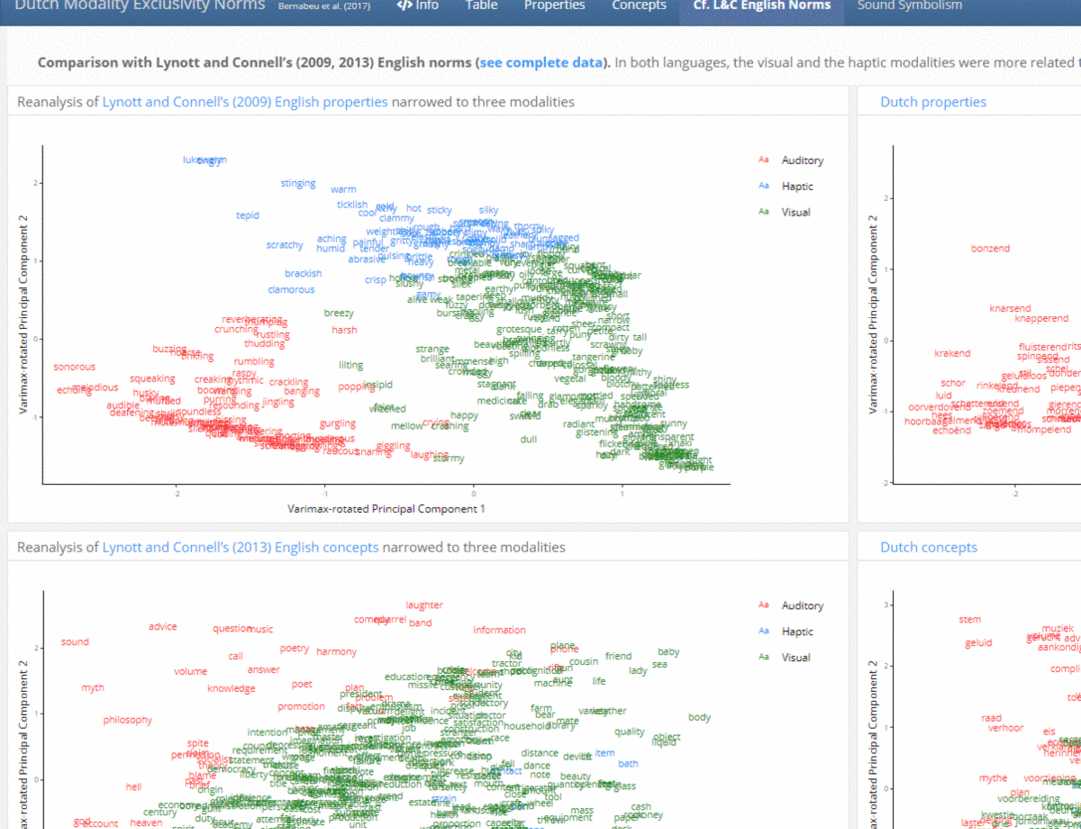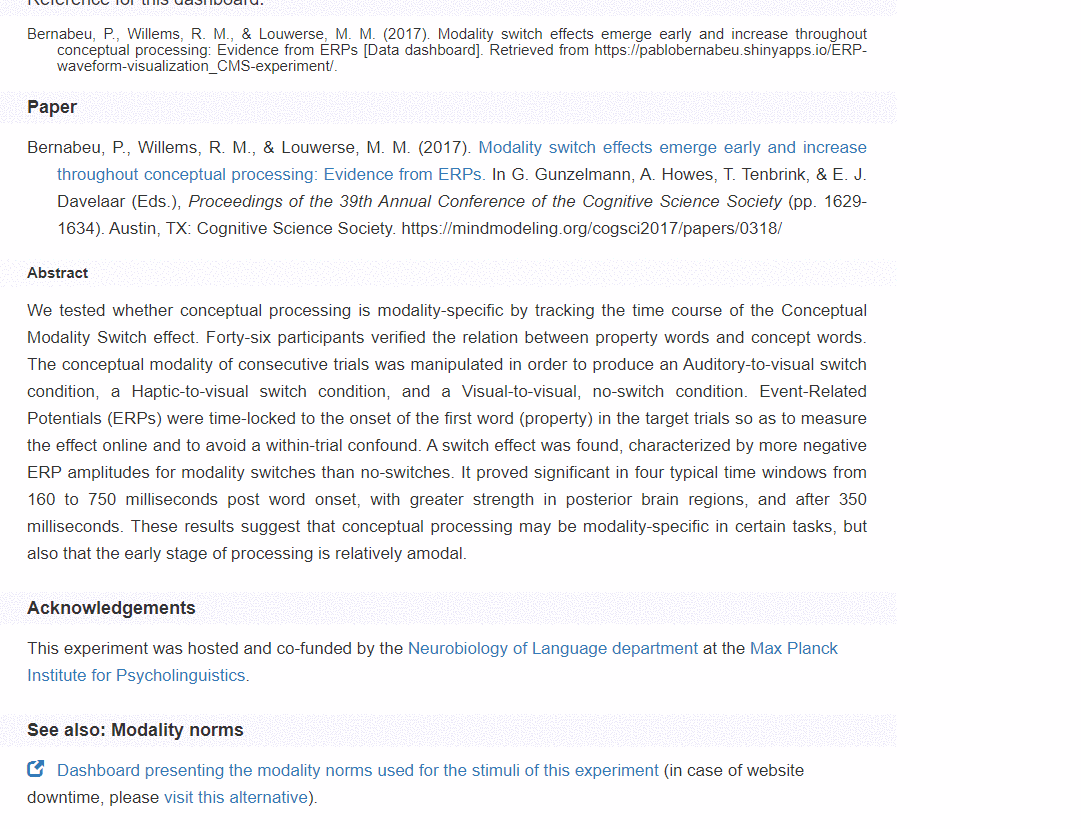
Trade-offs among dashboards
Next, we will practise with three dashboard types—Flexdashboard, Shiny and Flexdashboard-Shiny—and with the suitable hosting platforms. Firstly, the strength of Flexdashboard (example) is its basis on R Markdown, yielding an unmatched user interface (front-end). Secondly, the strength of Shiny (example) is the input reactivity (back-end) it offers, allowing users to download sections of data they select, in various formats. Last, Flexdashboard-Shiny (example) combines the best of both worlds.
★ Flexdashboard ★
★ ★ Shiny ★ ★
★ ★ ★ Flexdashboard-Shiny ★ ★ ★
Flexdashboard types are rendered as an HTML document—simple websites—, and can therefore be easily published on personal sites or RPubs. This is convenient because no special hosting is required. In contrast, Shiny and Flexdashboard-Shiny types offer greater features, but require Shiny servers. Fortunately, the shinyapps.io server is available for free, up to some usage limit. This server can host any of the three dashboards mentioned here. Another good option is presented by Binder environments, which can host the Shiny-type dashboards with no (explicit) limit. Yet, the Flexdashboard-Shiny type cannot be hosted in this server (as of January 2020, at least). Consequently, greater functionality may come at a cost for dashboards that have any considerable traffic, whereas dashboards with low traffic may do well on shinyapps.io. Knowing these trade-offs can help navigate usage limits, save on web hosting fees, and increase the availability of our dashboards online, as we can offer fall-back versions on different platforms, as in the example below:
… preferred-dashboard (in case of downtime, please visit this alternative)
Transforming dashboards into the different versions can be as easy as enabling or disabling some features, especially input reactivity. For instance, if we want to downgrade a Flexdashboard-Shiny to a Flexdashboard, to publish it outside of a Shiny server (see example), we must delete runtime:shiny from the header, and disable reactive features, as below.
``` r
# Number of words selected on sidebar
# reactive(cat(paste0('Words selected below: ', nrow(selected_props()))))
```Free accounts and tips
Hosting sites have specific terms of use. For instance, shinyapps.io has a free starter license with limited use. Free apps can handle a large but limited amount of data, and up to five apps may be created. Beyond this, RStudio offers a wide range of subscriptions starting at $9/month.
Memory and traffic limits of the free shinyapps.io account can sometimes present problems when heavy data data sets are used, or there are many visits to the app. The memory overload issue is often flagged as Shiny cannot use on-disk bookmarking, whereas excessive traffic may see the app not loading. Fortunately, usage limits need not always require a paid subscription or a custom server, thanks to the following workarounds:
- develop app locally as far as possible, and only deploy to shinyapps.io only at the last stage;
- prune data set, leaving only the necessary data;
- if necessary, unlink data by splitting it into different sets, reducing computational demands;
- if necessary, use various apps (five are allowed in each free shinyapps.io account);
- if necessary, link from the app to a PDF with visualisations requiring heavy, interlinked data. High-resolution plots can be rendered into a PDF document in a snap, using code such as below.
pdf('List of plots per page', width = 13, height = 5)
print(plot1)
print(plot2)
# ...
print(plot150)
dev.off()Conveniently, all text in a PDF—even in plots—is indexed, so it can be searched [ Ctrl+f / Cmd+f / 🔍 ] (see example). Furthermore, you may also merge the rendered PDF with any other documents.
Prerequisites and suggestions for participation in each workshop
Necessary: laptop or computer with R and RStudio installed, or access to RStudio Cloud; familiarity with the content of the preceding workshops through the web links herein.
Suggested: having your own data and R code ready (on a Github repository if participating in Workshop 4); participation in some of the preceding workshops.
Datathons: creating reproducible documents and dashboards
In these coding meetups, participants collaborate to create reproducible documents or dashboards using the data and software they prefer (see examples). Since the work can be split across different people and sections, some nice products may be achieved within a session. Any programming languages may be used.
Data used: academic or non-academic data of your own or from open-access sources such as OSF, scientific journals, governments, international institutions, NGOs, etc.
- Inspired by the great Reprohacks, content suggestions are encouraged. That is, if you’d like to have a reproducible document or dashboard created for a certain, open-access data set, please let us know, and some participants may take it on. Suggestions may be posted as issues or emailed to p.bernabeu@lancaster.ac.uk.
- Inspired by the great Reprohacks, content suggestions are encouraged. That is, if you’d like to have a reproducible document or dashboard created for a certain, open-access data set, please let us know, and some participants may take it on. Suggestions may be posted as issues or emailed to p.bernabeu@lancaster.ac.uk.
Purposes
collaborating to visualise data in novel ways using reproducible documents or interactive dashboards. For this purpose, participants sometimes draw on additional data to look at a bigger picture;
reflecting on the process by reviewing the techniques applied and challenges encountered.
Output: A key aspect of datathons is the creation of output. Documents and dashboards are (co-)authored by the participants who work on them, who can then publish them on their websites, or on RPubs, Binder, Shinyapps or custom servers. Time constraints notwithstanding, a lot of this output may be very enticing for further development by the same participants, or even by other people if the code is shared online. Just like with data, an attribution licence can be attached to the code.
Prerequisites and suggestions for participation in datathons
Necessary: basic knowledge of reproducible documents or dashboards.
Suggested: familiarity with the development of reproducible documents or dashboards; an idea about the data you’d like to work with and the kind of document or dashboard you want to create.
Contact
Please submit any queries or requests by posting an issue or emailing p.bernabeu@lancaster.ac.uk.