scopusflow is a reproducible, quota-aware workflow layer over the Elsevier Scopus Search API. It turns one-off bibliographic queries into inspectable plans, retrieves records safely with pagination, rate-limit handling, retry with back-off and optional resumable caching, normalises them to a stable tidy schema, tracks changes in DOI sets over time and compares publication trends across topics.
Scopus is a trademark of Elsevier. scopusflow is an independent client and is not affiliated with or endorsed by Elsevier. You will need your own Elsevier API key and should use it under Elsevier’s API terms.
Installation
# install.packages("pak")
pak::pak("pablobernabeu/scopusflow")API key
scopusflow never stores your key. It is read, in order, from the api_key argument, the scopusflow.api_key option, or the SCOPUS_API_KEY environment variable. Store it in ~/.Renviron:
SCOPUS_API_KEY=your-key-here
# Optional, for off-campus access to subscriber content:
SCOPUS_INST_TOKEN=your-institutional-token
library(scopusflow)
scopus_has_key()
#> [1] FALSEQuick start (offline)
Every retrieval returns a scopus_records tibble with a stable schema, so the downstream helpers can be shown without any network access:
# A couple of records in the shape the Scopus API returns them.
raw <- list(entry = list(
list(`dc:identifier` = "SCOPUS_ID:1", `prism:doi` = "10.1000/aaa",
`dc:title` = "A reproducible workflow", `dc:creator` = "Smith J.",
`prism:publicationName` = "J. Bibliometrics",
`prism:coverDate` = "2020-05-01", `citedby-count` = "12"),
list(`dc:identifier` = "SCOPUS_ID:2", `prism:doi` = "10.1000/bbb",
`dc:title` = "Quota-aware querying", `dc:creator` = "Doe A.",
`prism:publicationName` = "Scientometrics Today",
`prism:coverDate` = "2021-01-10", `citedby-count` = "3")
))
records <- scopus_records(raw, query = "TITLE-ABS-KEY(workflow)")
records
#> <scopus_records> 2 records
#> query: "TITLE-ABS-KEY(workflow)"
#> # A tibble: 2 × 9
#> entry_number scopus_id doi title authors year date publication citations
#> <int> <chr> <chr> <chr> <chr> <int> <chr> <chr> <int>
#> 1 1 1 10.100… A re… Smith … 2020 2020… J. Bibliom… 12
#> 2 2 2 10.100… Quot… Doe A. 2021 2021… Scientomet… 3
# Extract and deduplicate DOIs.
scopus_extract_dois(records)
#> [1] "10.1000/aaa" "10.1000/bbb"
# Track what changed since a previous retrieval.
scopus_diff_dois(old = "10.1000/aaa", new = c("10.1000/aaa", "10.1000/bbb"))
#> <scopus_doi_diff> 1 added, 0 removed, 1 unchanged
#> # A tibble: 2 × 2
#> doi status
#> <chr> <fct>
#> 1 10.1000/bbb added
#> 2 10.1000/aaa unchanged
# Tally the most frequent sources or authors.
scopus_top(records, by = "source")
#> # A tibble: 2 × 2
#> value n
#> * <chr> <int>
#> 1 J. Bibliometrics 1
#> 2 Scientometrics Today 1
# Hand off to bibliometrix-style analysis.
as_bibliometrix(records)
#> AU TI SO DI PY TC UT
#> 1 SMITH J. A REPRODUCIBLE WORKFLOW J. BIBLIOMETRICS 10.1000/aaa 2020 12 1
#> 2 DOE A. QUOTA-AWARE QUERYING SCIENTOMETRICS TODAY 10.1000/bbb 2021 3 2
#> DB
#> 1 SCOPUS
#> 2 SCOPUSLive workflow
With a key configured, the same pieces compose into a real retrieval. These calls contact the API and consume quota, so they are not run here:
# 1. Compose a field-tagged query, then a reproducible plan partitioned by
# year to stay under the API's start < 5000 ceiling.
q <- scopus_query("perovskite", "solar cell", .field = "TITLE-ABS-KEY")
plan <- scopus_plan(q, years = 2012:2022, partition = "year")
# 2. Size it before spending quota.
scopus_count(q, years = 2012:2022)
# 3. Execute, caching each year so an interrupted run can resume.
records <- scopus_fetch_plan(plan, cache_dir = scopus_cache_dir(), resume = TRUE)
# 4. Save the DOIs for import into a reference manager (e.g. Zotero).
scopus_extract_dois(records, file = file.path(tempdir(), "dois.csv"))
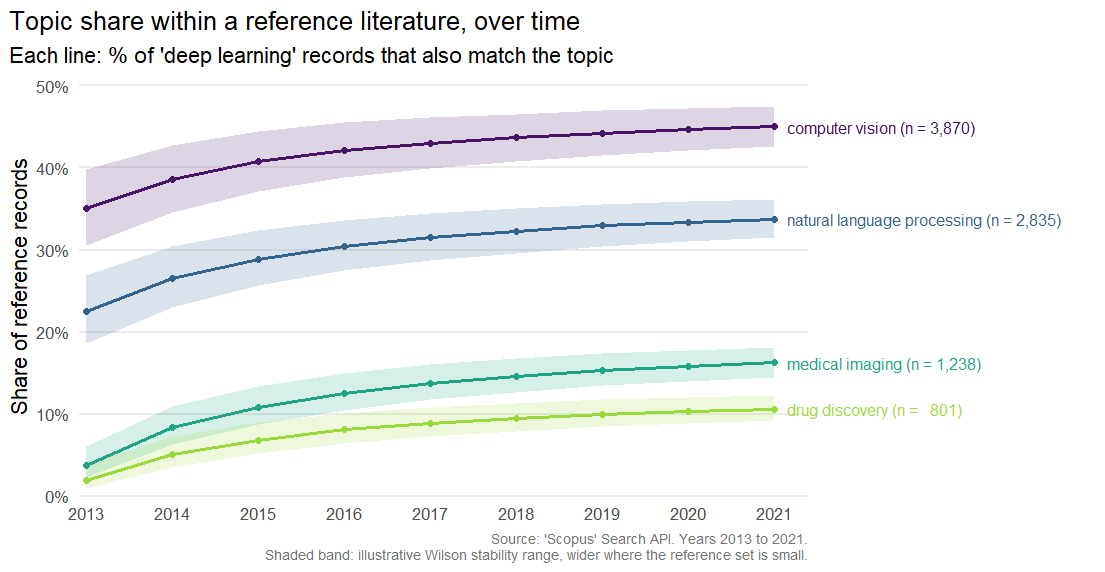
# 5. Compare how a method spreads across application areas over time.
cmp <- scopus_compare_topics(
reference_query = "deep learning",
comparison_terms = c("computer vision", "drug discovery", "medical imaging"),
years = 2013:2022,
field = "TITLE-ABS-KEY"
)
plot_scopus_comparison(cmp)
# 6. Read the abstract of a known record, or harvest a whole large query past
# the 5000-record ceiling with cursor pagination.
scopus_abstract("10.1038/s41586-019-0001-1")
all_records <- scopus_fetch("TITLE-ABS-KEY(microplastics)", cursor = TRUE)Quotas, rate limits and errors
The Scopus API enforces a weekly quota and a short-term rate limit, and ordinary offset paging returns at most the first 5000 records of any query (use scopus_fetch(cursor = TRUE) to go beyond that). scopusflow works within these limits rather than around them. It requests the largest page each view allows, 200 records for STANDARD and 25 for COMPLETE, so that a retrieval uses as few requests, and as little quota, as it can. This is the same approach rscopus takes. The quota and rate-limit headers are parsed by scopus_quota(), transient failures such as HTTP 429 and the 5xx range are retried with back-off that honours Retry-After, and an offset-paged query is capped at 5000 records with a warning that suggests cursor paging or partitioning by year. A failure arrives as a typed condition, so a workflow can respond to it in code:
tryCatch(
scopus_count("..."),
scopus_error_no_key = function(e) message("Set SCOPUS_API_KEY first."),
scopus_error_rate_limit = function(e) message("Slow down: ", conditionMessage(e)),
scopus_error = function(e) message("Scopus problem: ", conditionMessage(e))
)All scopus_error_* conditions inherit from scopus_error.
How it compares
| Package | Focus | Relationship to scopusflow |
|---|---|---|
rscopus |
Low-level Scopus API wrapper | scopusflow sits at a higher workflow layer (plans, quotas, caching, diffs) and calls the API directly through httr2
|
openalexR, pubmedR, dimensionsR, rcrossref
|
Other bibliographic databases | Complementary, covering different sources |
bibliometrix |
Science mapping and analysis | Downstream, and fed by as_bibliometrix()
|
Limitations
A few limits are worth keeping in mind. The Scopus Search API returns at most 5000 records for a single query, so a large search is best partitioned by year. as_bibliometrix() maps the core descriptive fields the Search API returns, and an analysis that needs full affiliations or cited references will still call for a complete Scopus export. What you can retrieve also depends on your Elsevier entitlement, and some fields are available only in the COMPLETE view and to subscribers.
Citation
citation("scopusflow")Contributing
Issues and pull requests are welcome. The contributing guide describes the development setup and the conventions the package follows, and everyone taking part is asked to honour the Code of Conduct.
Alongside the per-commit checks on Windows, macOS and several versions of R, a scheduled job re-checks the package every other day against the current and development versions of its dependencies, so that breakage from an upstream change is caught early. The contributing guide describes how it reports, and tries to resolve, any problem it finds.