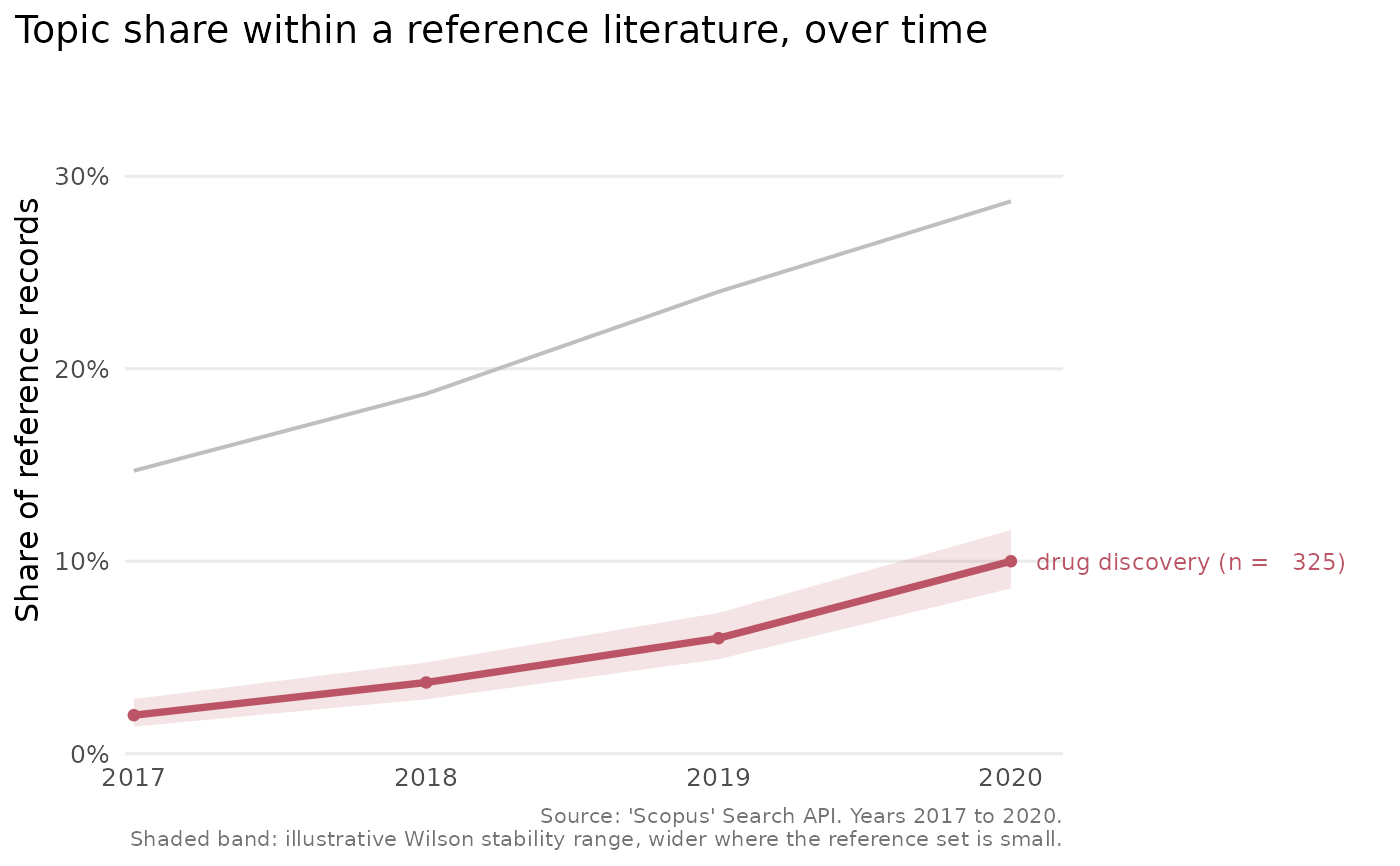
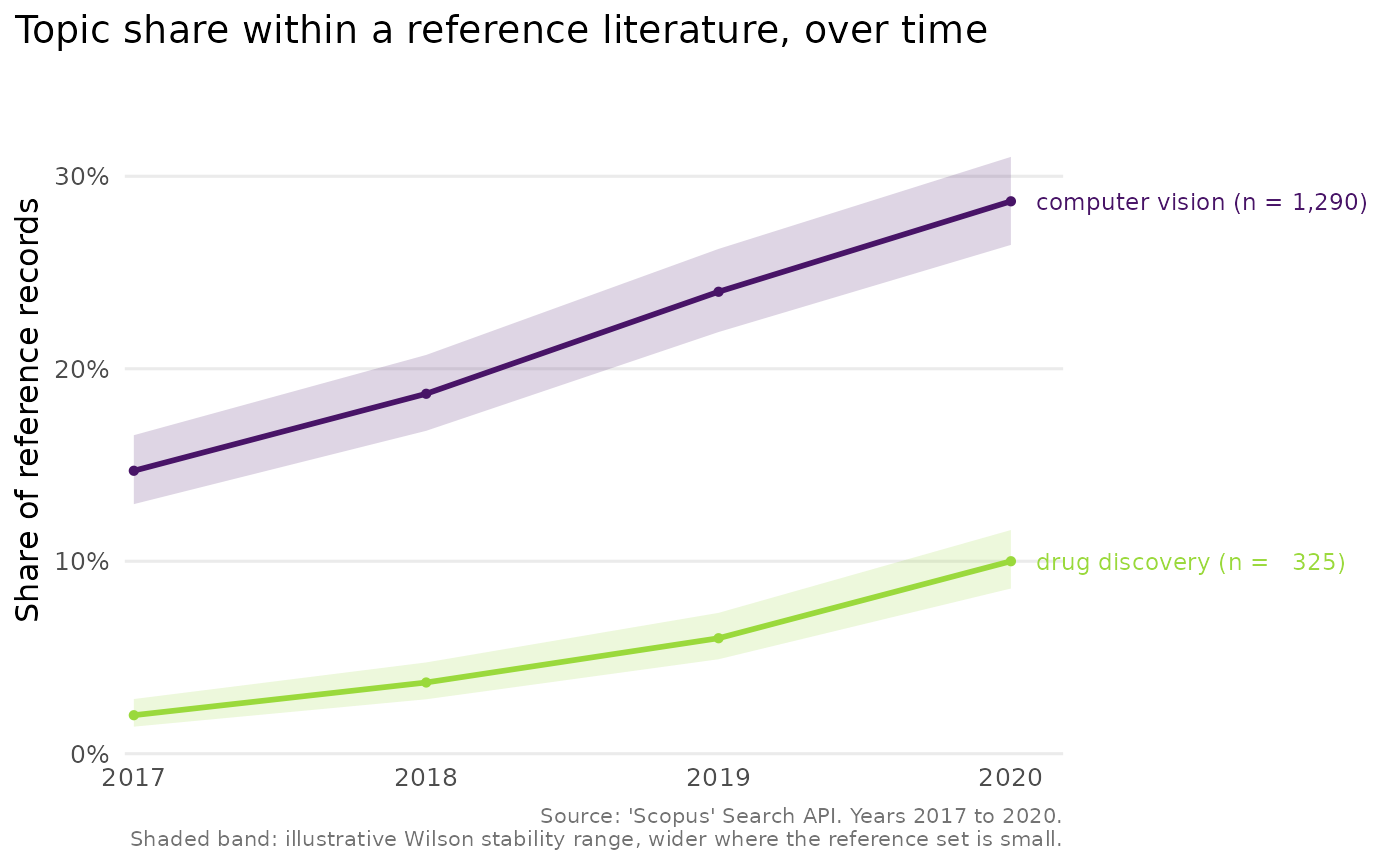
Draws a line chart of each comparison topic's share of the reference
literature over time, from the output of scopus_compare_topics(). The chart
uses integer year breaks, a colour-blind-safe palette and, for a handful of
topics, labels the lines directly so the reader need not consult a legend.
Shaded bands convey how stable each yearly share is.
Usage
plot_scopus_comparison(
x,
pub_count_in_legend = TRUE,
highlight = NULL,
interval = TRUE,
...
)
# S3 method for class 'scopus_comparison'
autoplot(object, ...)Arguments
- x
A
scopus_comparisonobject fromscopus_compare_topics().- pub_count_in_legend
Logical. When
TRUE(the default), each topic's label carries its total record count, for exampleeffect size (n = 1,204).- highlight
Optional character scalar naming one comparison topic to draw the eye to. The named topic is drawn in an accent colour, and the others in grey, which is useful when one topic is the focus of a figure.
- interval
Logical. When
TRUE(the default), a shaded band around each line shows a Wilson interval on the yearly share. See Details for how to read it.- ...
Currently unused, present for S3 consistency.
- object
A
scopus_comparisonobject (for theautoplot()method).
Value
A ggplot2::ggplot object. Printing it draws the plot.
Details
This needs the suggested package ggplot2 and raises an informative error when it is absent. The chart shows the comparison topics alone, since the reference is the 100% denominator against which they are measured. A year for which the reference has no records carries no defined share and is omitted, which is noted in the caption.
The shaded band is a Wilson score interval computed from the comparison count and the reference count for each year. 'Scopus' returns exact counts rather than a sample, so the band is not a confidence interval in the inferential sense. It is best read as an illustrative stability range: it is wide where the reference set for a year is small, and so the share would move easily, and narrow where the reference set is large. It says nothing about query wording, indexing lag or coverage, which are the larger real uncertainties.
Examples
cmp <- tibble::tibble(
query = "q", query_type = "comparison",
abridged_query = rep(c("computer vision", "drug discovery"), each = 4),
year = rep(2017:2020, 2), n = c(220, 280, 360, 430, 30, 55, 90, 150),
reference_n = rep(1500, 8),
comparison_percentage = c(14.7, 18.7, 24, 28.7, 2, 3.7, 6, 10),
average_comparison_percentage = rep(c(21.5, 5.4), each = 4)
)
class(cmp) <- c("scopus_comparison", class(cmp))
plot_scopus_comparison(cmp)
 plot_scopus_comparison(cmp, highlight = "drug discovery")
plot_scopus_comparison(cmp, highlight = "drug discovery")