Secure and scalable speech transcription for local and HPC
Software

Abstract
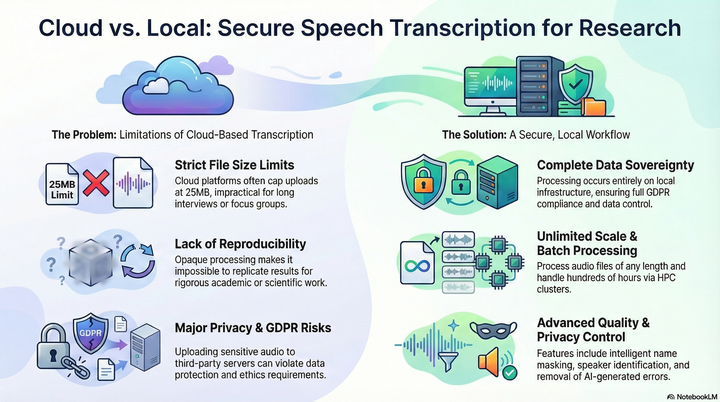
Cloud-based speech-to-text services are convenient, but they often have file size limits, lack transparency for reproducible research, and can pose privacy risks under regulations like GDPR. To address these limitations, this project introduces a production-ready, local transcription workflow using OpenAI's Whisper models. This self-contained system ensures complete data sovereignty and is designed for scalability, supporting batch operations on high-performance computing (HPC) clusters with GPU acceleration. The workflow includes advanced quality control, such as algorithms to detect and remove AI-generated repetitions, context-aware name masking for privacy, speaker diarisation, and a flexible audio enhancement pipeline. Implemented as a single Python script, this system offers a robust, reproducible, and secure alternative for academic and enterprise transcription.
Citation
![]()
If you use this workflow in your research, please cite:
Bernabeu, P. (2025). Secure and scalable speech transcription for local and HPC (Version 1.0.0) [Computer software]. Zenodo. https://doi.org/10.5281/zenodo.17624830
The recommended BibTeX entry is:
@misc{secure_local_HPC_speech_transcription,
author = {Bernabeu, Pablo},
title = {Secure and scalable speech transcription for local and {HPC}},
year = {2025},
publisher = {Zenodo},
version = {1.0.0},
doi = {10.5281/zenodo.17624830},
url = {https://doi.org/10.5281/zenodo.17624830}
}