Secure and scalable speech transcription for local and HPC
The Evolution of Transcription Technology
The landscape of speech-to-text transcription has undergone a remarkable transformation in recent years, driven by the proliferation of generative artificial intelligence (genAI) tools. From basic dictation software to sophisticated neural networks, transcription technology has evolved to handle diverse audio conditions, multiple languages and complex speech patterns with unprecedented accuracy.
At the forefront of this revolution stands OpenAI’s Whisper model family, released as open-source tools that have democratised access to state-of-the-art automatic speech recognition (ASR) capabilities. True to the “Open” in OpenAI’s original mission, these models have become the gold standard for transcription tasks, offering researchers and developers robust, multilingual speech recognition that rivals proprietary commercial solutions. The Whisper architecture, trained on 680,000 hours of multilingual audio data, represents a paradigm shift toward generalisable, production-ready ASR systems that can handle real-world audio conditions without extensive fine-tuning.
Chatbots and Limitations
Large Language Model chatbots such as ChatGPT and Google Gemini allow uploading recordings and having them transcribed using advanced models such as Whisper. However, this route has several limitations that make it unsuitable for serious research and production workflows.
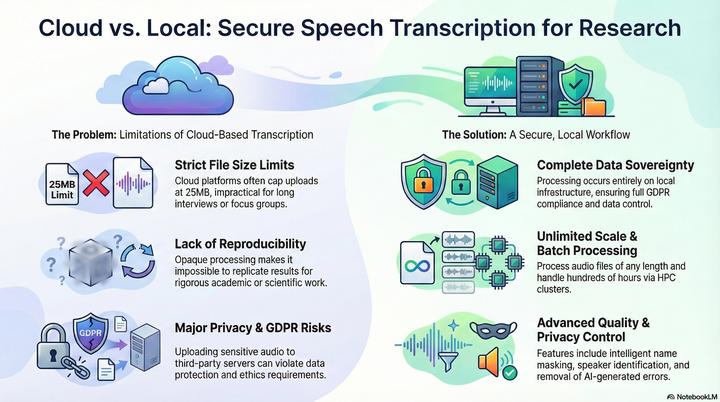
First, cloud-based chatbot interfaces impose strict file size limitations, typically restricting uploads to recordings of 25MB or less, which translates to roughly 20-30 minutes of audio content. This constraint renders them impractical for transcribing lengthy interviews, focus groups, or extended research sessions that often span multiple hours.
Second, chatbot-based transcription provides significantly less reproducibility than local workflows. The exact model versions, processing parameters and post-processing steps remain opaque to users, making it impossible to replicate results or maintain consistent transcription quality across different sessions. This lack of transparency is particularly problematic for academic research where methodological rigor and reproducibility are paramount.
Third, when working with confidential or sensitive recordings, cloud-based solutions introduce substantial privacy and compliance risks. While some platforms offer temporary chat modes that allegedly prevent model training using uploaded content, this approach still requires transmitting sensitive audio data to third-party servers, potentially violating institutional policies, research ethics requirements, or data protection regulations such as the General Data Protection Regulation (GDPR).
Addressing the Limitations: Python-Supported Local Workflow
The constraints of cloud-based transcription can be comprehensively addressed by implementing a secure, self-contained, local workflow that leverages the same advanced models while maintaining complete control over data processing and storage. This production-grade transcription system offers several compelling advantages over cloud alternatives:
Complete Data Sovereignty and GDPR Compliance
By executing all processing on local or institutional infrastructure, the workflow ensures that sensitive audio content never leaves the controlled environment. This approach provides full GDPR compliance and satisfies the stringent data protection requirements common in academic research, healthcare and corporate environments. The system downloads pre-trained models once and runs them entirely offline, eliminating ongoing data transmission concerns.
Unlimited Scale and Batch Processing Capabilities
Unlike cloud services with arbitrary file size limitations, the local workflow can process audio files of any length and handle large-scale batch operations. The system supports parallel processing across multiple graphics processing unit (GPU) nodes in high-performance computing (HPC) environments, enabling researchers to transcribe hundreds of hours of audio content efficiently. The intelligent job scheduling system automatically detects available files and optimises resource allocation across computing clusters.
Reproducible and Auditable Processing
Every aspect of the transcription pipeline is configurable and documented, from model selection and audio enhancement parameters to text processing rules and privacy protection settings. This transparency enables researchers to maintain detailed methodological records, reproduce results across different time periods and adjust processing parameters to optimise for specific audio conditions or research requirements.
Advanced Quality Control and Post-Processing
The workflow incorporates sophisticated quality improvement algorithms that address common artefacts introduced by generative artificial intelligence models. These include automatic detection and removal of spurious repetitions, intelligent punctuation correction and context-aware personal name masking that prevents false positives whilst maintaining conversation flow and readability.
Flexible Audio Enhancement Pipeline
The system includes an optional audio enhancement stage that applies spectral noise reduction, dynamic range compression and signal amplification to improve transcription quality for challenging audio conditions. This preprocessing stage uses the first 0.5 seconds of each recording as a noise reference, enabling adaptive enhancement that adjusts to different recording environments.
Multi-Model Support and Future-Proofing
While optimised for OpenAI’s Whisper models, the architecture supports any HuggingFace-compatible ASR model, enabling researchers to experiment with specialised models for domain-specific applications or incorporate newer model releases as they become available. The modular design ensures long-term sustainability and adaptability to evolving transcription technologies.
Example Output
The repository includes example output files demonstrating the system’s transcription quality and formatting. Below is an example transcript:
Technical Architecture
The system is implemented as a monolithic Python script, transcription.py, which integrates all core components into a single, self-contained processing engine. This architectural choice prioritises simplicity, maintainability and ease of deployment without external module dependencies. The script orchestrates a multi-stage pipeline and resolves several critical technical challenges through a unified command-line interface.
Core Technical Solutions
Challenge 1: GenAI-Generated Repetitions A significant hurdle with generative AI models like Whisper is their tendency to produce spurious repetitions—a form of hallucination where the model gets “stuck” and repeats phrases.
- Solution: The
--fix-spurious-repetitionsflag activates a sophisticated repetition detection algorithm. It analyses text patterns to distinguish between intentional, natural emphasis and AI-generated artefacts by considering the frequency, context, and structure of repeated segments.
Challenge 2: GenAI-Generated Language Switching Whisper models can erroneously switch languages when interpreting phonetically ambiguous sounds.
- Solution: The
--languageargument constrains the model to the designated language, preventing unwanted language switches while maintaining transcription accuracy.
Challenge 3: Intelligent and Private Name Masking A key challenge is reliably identifying personal names while avoiding the masking of common words or technical terms (false positives).
- Solution: The system uses a sophisticated, multi-tiered approach. The default is a curated database of over 1,793 names across nine languages, refined to minimise false positives on common words. For broader coverage, optional databases from Facebook (over 1.7 million names) can be enabled, though this increases the risk of false positives. Users can also provide custom lists of names to exclude from masking, which is useful for preserving the names of public figures or research team members.
Challenge 4: Scalable High-Performance Computing (HPC) Integration The workflow is designed for large-scale batch processing in HPC environments using a Simple Linux Utility for Resource Management (SLURM) scheduler.
- Solution: A collection of submission scripts provides dynamic job array sizing, automatically matching the number of jobs to the number of input files. The system intelligently optimises resource use by prioritising GPU allocation with a graceful fallback to CPU, ensuring continuous operation. It also includes comprehensive error detection and recovery. Users can override default HPC resource allocations using the
--memoryand--time-limitarguments for exceptionally large or complex files.
Challenge 5: Reproducible and Stable Environments Creating a consistent Python environment across different platforms can be difficult due to dependency conflicts.
- Solution: The project includes platform-agnostic setup scripts that automatically detect and adapt to different HPC module systems. They manage complex dependencies, particularly for PyTorch and CUDA, and use version pinning to ensure stability and reproducibility.
Challenge 6: Speaker Attribution (Diarisation) Identifying who is speaking in a multi-speaker recording is a common requirement.
- Solution: The system integrates
pyannote.audiofor speaker diarisation, which can be enabled with the--speaker-attributionflag. This feature requires a HuggingFace user access token for thepyannote/speaker-diarization-3.1model.
Describing the Method in Publications
For researchers incorporating this workflow into their methodology, the following description provides a comprehensive yet concise summary suitable for academic publications:
Audio recordings were transcribed using OpenAI’s Whisper large-v3 model, a state-of-the-art automatic speech recognition system (Batista, 2024). The transcription workflow maintained full GDPR compliance through a local implementation where the pre-trained model was downloaded from the OpenAI repository on the Hugging Face platform and executed entirely on institutional high-performance computing infrastructure, ensuring no audio data or transcription content was transmitted to or processed by third-party services.
The pipeline incorporated several processing stages: optional audio enhancement for improved signal quality using spectral noise reduction and dynamic range compression, configurable language specification to prevent unwanted language switching artefacts, automatic detection and removal of spurious text repetitions generated by the AI model, comprehensive spelling corrections and text formatting, and privacy protection through intelligent personal name masking that replaced detected names with anonymised placeholders whilst avoiding false positives on common conversational words.
Quality control measures included automatic repetition pattern detection to remove AI-generated artefacts, punctuation spacing corrections and context-aware text processing to maintain natural conversation flow. The system generated both plain text transcripts and formatted Microsoft Word documents with comprehensive processing metadata and timestamps for reproducibility and audit purposes.
Reference
Batista, J. R. (2024). Learn OpenAI Whisper: Transform your understanding of GenAI through robust and accurate speech processing solutions. Packt Publishing Ltd.
Licence
This workflow is made available under the Creative Commons 4.0 Attribution 4.0 International licence.
Citation
![]()
If you use this workflow in your research, please cite:
Bernabeu, P. (2025). Secure and scalable speech transcription for local and HPC (Version 1.0.0) [Computer software]. Zenodo. https://doi.org/10.5281/zenodo.17624830
The recommended BibTeX entry is:
@misc{secure_local_HPC_speech_transcription,
author = {Bernabeu, Pablo},
title = {Secure and scalable speech transcription for local and {HPC}},
year = {2025},
publisher = {Zenodo},
version = {1.0.0},
doi = {10.5281/zenodo.17624830},
url = {https://doi.org/10.5281/zenodo.17624830}
}Conclusion
This comprehensive transcription workflow represents a mature, production-ready alternative to cloud-based transcription services, specifically designed to meet the demanding requirements of research and development environments. By combining state-of-the-art AI models with robust engineering practices within a monolithic, easily maintainable architecture, the system delivers high-quality transcription capabilities whilst maintaining complete control over data processing, privacy protection and quality assurance.
The workflow’s emphasis on reproducibility, scalability and simplicity makes it particularly valuable for research applications where methodological rigour and long-term sustainability are essential. As speech recognition technology continues to evolve, this straightforward architecture ensures that researchers can incorporate new developments whilst maintaining the stability and clarity required for research workflows.
For organisations seeking to leverage advanced transcription capabilities without compromising data sovereignty or processing control, this workflow provides a compelling foundation for building sophisticated speech processing pipelines that can grow and adapt with emerging technologies and evolving research requirements.