


This dashboard presents the data and analyses of a set of modality exclusivity norms for Dutch. Various tabs and interactive plots are available. In addition, the data set is available in CSV format and Excel format including column definitions.
The norms, which are ratings of linguistic stimuli, served a twofold purpose: first, the creation of linguistic stimuli (Bernabeu, 2018; see also Speed & Majid, 2017), and second, a conceptual replication of Lynott and Connell’s (2009, 2013) analyses. In the collection of the ratings, forty-two respondents completed surveys for the properties or the concepts separately. Each word was rated by eight participants on average, with a minimum of five (e.g., for bevriezend) and a maximum of ten ratings per word (e.g., for donzig). The instructions to participants were similar to those used by Lynott and Connell (2009, 2013), except that we elicited three modalities (auditory, haptic, visual) instead of five.
‘This is a stimulus validation for a future experiment. The task is to rate how much you experience everyday’ [properties/concepts] ‘using three different perceptual senses: feeling by touch, hearing and seeing. Please rate every word on each of the three senses, from 0 (not experienced at all with that sense) to 5 (experienced greatly with that sense). If you do not know the meaning of a word, leave it blank.’

These norms were validated in an experiment demonstrating that shifts across trials with different dominant modalities incurred semantic processing costs (Bernabeu, Willems, & Louwerse, 2017). All data for that study are available, including a dashboard.
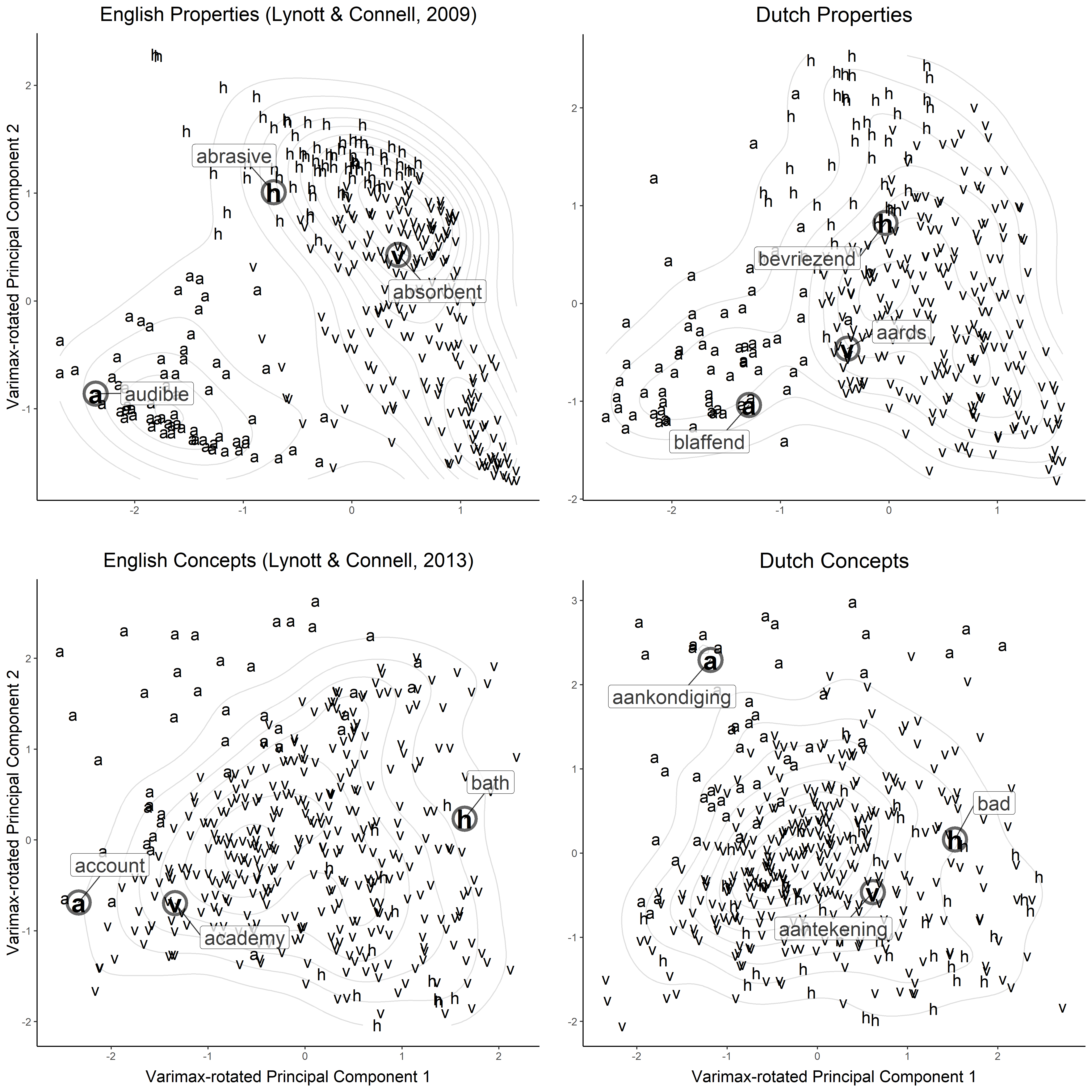
The properties and the concepts may also be consulted together on a table. Distinct relationships emerged among the modalities, with the visual and haptic modalities being more related to each other than to the auditory modality. This ties in with findings that, in conceptual processing, modalities can be collated based on language statistics (Louwerse & Connell, 2011). Furthermore, properties were found to be more strongly perceptual than concepts (cf. English norms by Lynott & Connell, 2009, 2013).

Figure 2. Dutch norms compared to English norms (reanalysis of Lynott & Connell, 2009, 2013, narrowed to three modalities) based on a principal component analysis of the auditory, haptic, and visual ratings for each word. Letters indicate the dominant modality of each word (a = auditory, h = haptic, v = visual), and contours further display the degree of consistency of the modalities. Github
The norms also served to investigate sound symbolism, which is the relation between the form of words and their meaning. The form of words rests on their sound more than on their visual or tactile properties (at least in spoken language). Therefore, auditory ratings should more reliably predict the lexical properties of words (length, frequency, distinctiveness) than haptic or visual ratings would. Lynott and Connell’s (2013) findings were replicated, as auditory ratings were either the best predictor of lexical properties, or yielded an effect that was opposite in polarity to the effects of haptic and visual ratings. The present analyses and further ones will be reported in a forthcoming paper.
All data and code are available for re-use under a CC BY licence, by citing the source:

Bernabeu, P. (2018). Dutch modality exclusivity norms for 336 properties and 411 concepts [Data dashboard]. Retrieved from https://pablobernabeu.shinyapps.io/Dutch-Modality-Exclusivity-Norms/.
This research was greatly supported by the supervision from Max Louwerse and Roel Willems; the financial help from Tilburg University; Wendy Leijten’s help with the translations; and the forty-two students from Tilburg University and Radboud University who completed the surveys.
Baayen, R. H., Piepenbrock, R., & van Rijn, H. (1993). The CELEX Lexical Database [CD-ROM]. Philadelphia: Linguistic Data Consortium, University of Pennsylvania.
Bernabeu, P. (2018). Dutch modality exclusivity norms for 336 properties and 411 concepts [Unpublished manuscript]. School of Humanities, Tilburg University, the Netherlands. https://psyarxiv.com/s2c5h.
Bernabeu, P., Willems, R. M., & Louwerse, M. M. (2017). Modality switch effects emerge early and increase throughout conceptual processing: Evidence from ERPs. In G. Gunzelmann, A. Howes, T. Tenbrink, & E. J. Davelaar (Eds.), Proceedings of the 39th Annual Conference of the Cognitive Science Society (pp. 1629-1634). Austin, TX: Cognitive Science Society. https://doi.org/10.31234/osf.io/a5pcz.
Brysbaert, M., Warriner, A.B., & Kuperman, V. (2014).
Concreteness ratings for 40 thousand generally known English word
lemmas. Behavior Research Methods, 46, 3, 904-911.
https://doi.org/10.3758/s13428-013-0403-5.
Field, A. P., Miles, J., & Field, Z. (2012). Discovering Statistics Using R. London, UK: Sage.
Keuleers, E., Brysbaert, M. & New, B. (2010). SUBTLEX-NL: A new frequency measure for Dutch words based on film subtitles. Behavior Research Methods, 42, 3, 643-650. https://doi.org/10.3758/BRM.42.3.643.
Köhler, W. (1929). Gestalt Psychology. New York: Liveright.
Louwerse, M., & Connell, L. (2011). A taste of words: Linguistic context and perceptual simulation predict the modality of words. Cognitive Science, 35, 2, 381-98. https://doi.org/10.1111/j.1551-6709.2010.01157.x.
Lynott, D., & Connell, L. (2009). Modality exclusivity norms for 423 object concepts. Behavior Research Methods, 41, 2, 558-564. https://doi.org/10.3758/BRM.41.2.558.
Lynott, D., & Connell, L. (2013). Modality exclusivity norms for
400 nouns: The relationship between perceptual experience and surface
word form. Behavior Research Methods, 45, 2, 516-526.
https://doi.org/10.3758/s13428-012-0267-0.
Marian, V., Bartolotti, J., Chabal, S., & Shook, A. (2012).
CLEARPOND: Cross-Linguistic Easy-Access Resource for Phonological and
Orthographic Neighborhood Densities. PLoS ONE, 7, 8: e43230.
https://doi.org/10.1371/journal.pone.0043230.
Sourav, S., Kekunnaya, R., Shareef, I., Banerjee, S., Bottari, D., & Röder, B. (2019). A protracted sensitive period regulates the development of cross-modal sound-shape associations in humans. Psychological Science, 30, 10, 1473-1482. https://doi.org/10.1177/0956797619866625.
Speed, L. J., & Majid, A. (2017). Dutch modality exclusivity norms: Simulating perceptual modality in space. Behavior Research Methods, 49, 6, 2204-2218. https://doi.org/10.3758/s13428-017-0852-3.
Pablo Bernabeu. Email: pcbernabeu@gmail.com
Comparison with Lynott and Connell’s (2009, 2013) English norms (see complete data). In both languages, properties were visibly more perceptual than concepts.
Sound symbolism is the relation between the form of words and their meaning. The form of words rests on their sound more than on their visual or tactile properties (at least in spoken language). Therefore, auditory ratings should more reliably predict the lexical properties of words (length, frequency, distinctiveness) than haptic or visual ratings would (see external corpora). By means of regression analyses following Lynott and Connell (2013; see Table 6), we found that auditory ratings were either the best predictor of lexical properties, or yielded an effect that was opposite in polarity to the effects of haptic and visual ratings, thus supporting sound symbolism.
Standardised coefficients (\(\beta\)) presented below, followed by asterisks indicating significance (*p < .05; **p < .01; ***p < .001), and the standard error below. Regression assumptions observed, i.e., normal distribution of residuals (transformations attempted), largest variance inflation factor < 10 and its mean around 1, tolerance > 0.2 (Field, Miles, & Field, 2012). ‘PC’ = Kaiser-normalised, varimax-rotated principal component.
| Dependent | Auditory | Haptic | Visual |
|---|---|---|---|
| Age of acquisition | 0.04 (0.09) |
-0.01 (0.06) |
-0.21** (0.08) |
| Concreteness | -0.17 (0.09) |
0.07 (0.06) |
0.18* (0.08) |
| Contextual diversity | -0.07** (0.02) |
-0.00 (0.02) |
0.07** (0.02) |
| Distinctiveness PC | -0.05 (0.03) |
0.01 (0.02) |
-0.08** (0.03) |
| Frequency PC | 0.29* (0.12) |
-0.07 (0.07) |
0.19* (0.10) |
| Lemma frequency | 0.05 (0.09) |
-0.03 (0.06) |
0.15 (0.08) |
| Length PC | 0.06* (0.03) |
-0.02 (0.02) |
0.03 (0.02) |
| Number of letters | 0.11 (0.06) |
-0.09 (0.06) |
-0.01 (0.06) |
| Number of phonemes | 0.26* (0.11) |
-0.08 (0.07) |
0.11 (0.09) |
| Orthographic neighbours | -0.05* (0.02) |
0.01 (0.02) |
-0.01 (0.02) |
| Phonological neighbours | -0.06* (0.02) |
0.02 (0.02) |
-0.01 (0.02) |
| Word frequency | -0.07** (0.02) |
-0.00 (0.02) |
0.07** (0.02) |
| Dependent | Auditory | Haptic | Visual |
|---|---|---|---|
| Age of acquisition | -0.10* (0.04) |
-0.25*** (0.05) |
-0.29*** (0.05) |
| Concreteness | -0.05*** (0.01) |
0.11*** (0.02) |
0.12*** (0.02) |
| Contextual diversity | 0.20*** (0.05) |
0.06 (0.05) |
0.11* (0.05) |
| Distinctiveness PC | -0.03* (0.01) |
0.07*** (0.02) |
-0.01 (0.02) |
| Frequency PC | 0.23*** (0.05) |
-0.04 (0.05) |
0.10 (0.06) |
| Lemma frequency | 0.15** (0.05) |
-0.05 (0.05) |
0.12* (0.05) |
| Length PC | 0.05*** (0.02) |
-0.03* (0.02) |
-0.01 (0.02) |
| Number of letters | 0.05** (0.02) |
-0.07*** (0.02) |
-0.02 (0.02) |
| Number of phonemes | 0.06*** (0.02) |
-0.06** (0.02) |
-0.02 (0.02) |
| Orthographic neighbours | -0.05* (0.02) |
0.11*** (0.02) |
0.02 (0.02) |
| Phonological neighbours | -0.04* (0.02) |
0.11*** (0.02) |
0.01 (0.02) |
| Word frequency | 0.20*** (0.05) |
0.04 (0.05) |
0.12* (0.05) |

{kind=link}
{kind=link}