Secure and scalable speech transcription for local and HPC
Software

Abstract
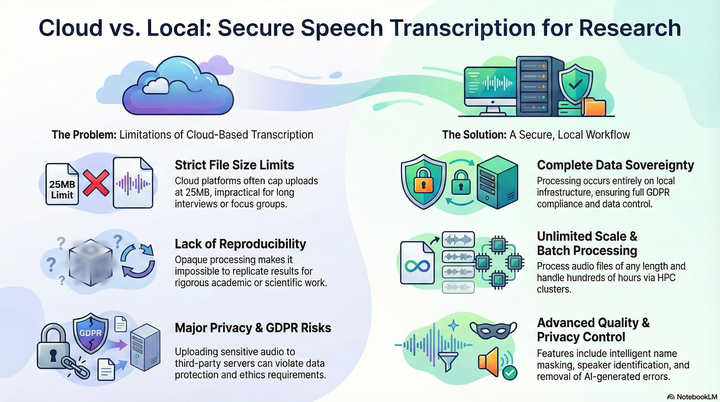
Cloud-based speech-to-text services are convenient, but they often have file size limits, lack transparency for reproducible research, and can pose privacy risks under regulations like GDPR. To address these limitations, this project introduces a production-ready, local transcription workflow using OpenAI's Whisper models. This self-contained system ensures complete data sovereignty and is designed for scalability, supporting batch operations on high-performance computing (HPC) clusters with GPU acceleration. The workflow includes advanced quality control, such as algorithms to detect and remove AI-generated repetitions, context-aware name masking for privacy, speaker diarisation, and a flexible audio enhancement pipeline. Implemented as a single Python script, this system offers a robust, reproducible, and secure alternative for academic and enterprise transcription.
How it works
with GPU acceleration"] C --> D["Remove AI-generated
repetitions"] C --> E["Context-aware name masking"] C --> F["Speaker diarisation"] D --> G["Reproducible and
GDPR-compliant transcript"] E --> G F --> G C --> H["Batch operations
on HPC clusters"]
Reference
![]()
If you use this workflow in your research, please cite:
Bernabeu, P. (2025). Secure and scalable speech transcription for local and HPC (Version 1.0.0) [Computer software]. Zenodo. https://doi.org/10.5281/zenodo.17624830
The recommended BibTeX entry is:
@misc{secure_local_HPC_speech_transcription,
author = {Bernabeu, Pablo},
title = {Secure and scalable speech transcription for local and {HPC}},
year = {2025},
publisher = {Zenodo},
version = {1.0.0},
doi = {10.5281/zenodo.17624830},
url = {https://doi.org/10.5281/zenodo.17624830}
}Podcast
Created using NotebookLM, with all the benefits and blind spots of human editing.
Related references
S, R. M., V, A. R., Nelgikar, A., K, S., & Shahapur, S. (2025). Mindshare: An AI-Powered Video Processing and Sharing Platform for Learning, Collaboration, and Creative Expression. 2025 2nd International Conference on Intelligent Algorithms for Computational Intelligence Systems (IACIS), 1–7. https://doi.org/10.1109/IACIS65746.2025.11211476
Koenecke, A., Choi, A. S. G., Mei, K. X., Schellmann, H., & Sloane, M. (2024). Careless Whisper: Speech-to-Text Hallucination Harms. The 2024 ACM Conference on Fairness, Accountability, and Transparency, 1672–1681. https://doi.org/10.1145/3630106.3658996
Landesvatter, C., Behnert, J., & Bauer, P. C. (2025). Comparing Speech-to-Text Algorithms for Transcribing Voice Data from Surveys. Public Opinion Quarterly, 89(4), 1154–1166. https://doi.org/10.1093/poq/nfaf056
McGuire, M., & Larson-Hall, J. (2025). Assessing Whisper automatic speech recognition and WER scoring for elicited imitation: Steps toward automation. Research Methods in Applied Linguistics, 4(1), 100197. https://doi.org/10.1016/j.rmal.2025.100197
Meehan, K., McDermott, F., & Petropoulos, N. (2024). Evaluating Automatic Transcription Models Utilising Cloud Platforms. 2024 5th International Conference on Data Analytics for Business and Industry (ICDABI), 91–96. https://doi.org/10.1109/icdabi63787.2024.10800465
Roushan, R., Mishra, H., Yadav, L., Koppula, S., Tiwari, N., & Nataraj, K. S. (2024). Optimizing Speech Recognition for Medical Transcription: Fine-Tuning Whisper and Developing a Web Application. 2024 IEEE Conference on Engineering Informatics (ICEI), 1–6. https://doi.org/10.1109/icei64305.2024.10912421
Russell, S. O., Gessinger, I., Krason, A., Vigliocco, G., & Harte, N. (2024). What automatic speech recognition can and cannot do for conversational speech transcription. Research Methods in Applied Linguistics, 3(3), 100163. https://doi.org/10.1016/j.rmal.2024.100163
Yadav, A., Shrotriya, A., & Bairwa, A. K. (2025). Fine-Tuning OpenAI Whisper and DistilWhisper: An In-Depth Analysis. Smart Cyber Physical Systems, 589–603. https://doi.org/10.1007/978-981-96-2182-8_44
Abgrall, G., Chelly Dagdia, Z., Monnet, X., Zeitouni, K., & Arora, A. (2025). From vibe coding to vibe caring: what clinicians can learn. The Lancet, 406(10512), 1561–1562. https://doi.org/10.1016/s0140-6736(25)01807-0
Affolter, J., Martin, B., Epure, E. V., Meseguer-Brocal, G., & Kaplan, F. (2026). Scalable Music Cover Retrieval Using Lyrics-Aligned Audio Embeddings. Advances in Information Retrieval, 49–66. https://doi.org/10.1007/978-3-032-21289-4_4
Alshwiah, A. A. (2026). The role of artificial intelligence (AI) in assisting students with writing Zoom meeting minutes: a qualitative study. Cogent Education, 13(1). https://doi.org/10.1080/2331186x.2026.2652076
Alumäe, T., & Koenecke, A. (2025). Striving for open-source and equitable speech-to-speech translation. Nature, 637(8046), 551–553. https://doi.org/10.1038/d41586-024-04095-6
Anderson, C. B., & Fisher, D. H. (2025). Artificial Intelligence for Academic Libraries. https://doi.org/10.4324/9781003473602
Ariya, P., Khanchai, S., Intawong, K., & Puritat, K. (2025). Enhancing textile heritage engagement through generative AI-based virtual assistants in virtual reality museums. Computers &Amp; Education: X Reality, 7, 100112. https://doi.org/10.1016/j.cexr.2025.100112
Arruda, F. S., & Castaldelli-Maia, J. M. (2025). The future of addiction psychiatry. International Review of Psychiatry, 38(1-3), 80–93. https://doi.org/10.1080/09540261.2025.2566211
Arshad, H., Abdullah, T., Rehman, M., Hussain, A., Kanwal, F., & Parveen, M. (2025). Optimizer-Aware Fine-Tuning of Whisper Small with Low-Rank Adaption: An Empirical Study of Adam and AdamW. Information, 16(11), 928. https://doi.org/10.3390/info16110928
Arsuka, I. P. G. S., Fakhrurroja, H., & Pramesti, D. (2025). Flutter-Based Mobile App Featuring AI-Driven Recommendation System and Speech Recognition for Agriculture. 2025 IEEE International Conference on Networking, Intelligent Systems, and IoT (ICONS-IoT), 108–114. https://doi.org/10.1109/icons-iot65216.2025.11210976
Ashwin, M., Jha, S., Prasad, G., & Kumar, S. (2025). Fake it till you make it? AI hallucinations and ethical dilemmas in Anesthesia research and practice. Journal of Anaesthesiology Clinical Pharmacology, 41(3), 381–383. https://doi.org/10.4103/joacp.joacp_56_25
Atwany, H., Waheed, A., Singh, R., Choudhury, M., & Raj, B. (2025). Lost in Transcription, Found in Distribution Shift: Demystifying Hallucination in Speech Foundation Models. Findings of the Association for Computational Linguistics: ACL 2025, 23181–23203. https://doi.org/10.18653/v1/2025.findings-acl.1190
Barański, M., Jasiński, J., Bartolewska, J., Kacprzak, S., Witkowski, M., & Kowalczyk, K. (2025). Investigation of Whisper ASR Hallucinations Induced by Non-Speech Audio. ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1–5. https://doi.org/10.1109/icassp49660.2025.10890105
Basak, S., & Gowda, M. (2025). Wireless-Tap:
Biecek, P., & Samek, W. (2025). Model Science: Getting Serious About Verification, Explanation and Control of AI Systems. Ecai 2025. https://doi.org/10.3233/faia250784
Bogdanova-Beglarian, N. V., Blinova, O. V., Khokhlova, M. V., Sherstinova, T. Y., & Popova, T. I. (2024). Multiword Units in Russian Everyday Speech: Empirical Classification and Corpus-Based Studies. Speech and Computer, 187–200. https://doi.org/10.1007/978-3-031-77961-9_14
Borkar, J., & Smith, D. A. (2024). Mind the Gap:Analyzing Lacunae with Transformer-Based Transcription. Document Analysis and Recognition – ICDAR 2024 Workshops, 57–70. https://doi.org/10.1007/978-3-031-70642-4_4
Brickman, J., Gupta, M., & Oltmanns, J. R. (2025). Large Language Models for Psychological Assessment: A Comprehensive Overview. Advances in Methods and Practices in Psychological Science, 8(3). https://doi.org/10.1177/25152459251343582
Bylund, A., Revenäs, Å., Södersved Källestedt, M.-L., Lindblom, M., Söderlund, A., & Elvén, M. (2025). Physiotherapy students’ clinical skills training needs within the musculoskeletal area: an explorative study of stakeholders’ perceptions. Physiotherapy Theory and Practice, 42(4), 581–594. https://doi.org/10.1080/09593985.2025.2589908
C, M. D., Noor R, S., K, S., A, G., M, J., & S, P. P. (2025). InstaScript: Convert Voice Notes to Summarized Smart Notes using NLP. 2025 International Conference on Sustainable Communication Networks and Application (ICSCN), 1765–1770. https://doi.org/10.1109/icscn67106.2025.11308439
Calandruccio, L., Hariri, M., Buss, E., & Chaudhary, V. (2025). Masked-speech Recognition Using Human and Synthetic Cloned Speech. Trends in Hearing, 29. https://doi.org/10.1177/23312165251403080
Castelli, M., Sousa, M., Vojtech, I., Single, M., Amstutz, D., Maradan-Gachet, M. E., Magalhães, A. D., Debove, I., Rusz, J., Martinez-Martin, P., Sznitman, R., Krack, P., & Nef, T. (2025). Detecting neuropsychiatric fluctuations in Parkinson’s Disease using patients’ own words: the potential of large language models. Npj Parkinson’s Disease, 11(1). https://doi.org/10.1038/s41531-025-00939-8
Chan, S., Li, J., Yao, B., Mahmood, A., Huang, C.-M., Jimison, H., Mynatt, E. D., & Wang, D. (2025). “Mango Mango, How to Let The Lettuce Dry Without A Spinner?”: Exploring User Perceptions of Using An LLM-Based Conversational Assistant Toward Cooking Partner. Proceedings of the ACM on Human-Computer Interaction, 9(7), 1–35. https://doi.org/10.1145/3757442
Chandra Madhav, Y. R., Umar, M., Kiran, O. S., & Babu, P. A. (2025). Personality Detection Using Xlm-Roberta and Whisper. 2025 IEEE Pune Section International Conference (PuneCon), 1–6. https://doi.org/10.1109/punecon67554.2025.11379051
Charuau, D., & Harte, N. (2027). A multimodal perspective on adaptive communication: Extending the hyper- and hypo-articulation theory. Computer Speech &Amp; Language, 101, 101990. https://doi.org/10.1016/j.csl.2026.101990
Chua, Y. H. V., Dauwels, J., Rajalingam, P., Teo, C. L., & Styles, S. J. (2025). Testing individual and group markers of collaboration in a team-based learning classroom. Learning and Instruction, 100, 102215. https://doi.org/10.1016/j.learninstruc.2025.102215
Chung, Y., Hong, J., Lee, J., & Kim, E. (2026). Diagnosis-aware multitask fine-tuning of Whisper for dysarthric speech recognition. Speech Communication, 180, 103393. https://doi.org/10.1016/j.specom.2026.103393
Colonel, J. T., Hagler, C., Wismer, G., Curtis, L., Becker, J., Wisnivesky, J., Federman, A., & Pandey, G. (2025). CAtCh: Cognitive Assessment through Cookie Thief. 2025 IEEE International Conference on Digital Health (ICDH), 154–162. https://doi.org/10.1109/icdh67620.2025.00029
Correa-Carmona, Y., Böttger, D., Korsch, D., Holzmann, K. L., Alonso-Alonso, P., Pinos, A., Yon, F., Keller, A., Steffan-Dewenter, I., Bodesheim, P., Peters, M. K., & Brehm, G. (2026). LEPY: A Python pipeline for automated trait extraction from standardised Lepidoptera images. Ecological Informatics, 95, 103680. https://doi.org/10.1016/j.ecoinf.2026.103680
Czyżewski, A., Cygert, S., Marciniuk, K., Szczodrak, M., Harasimiuk, A., Odya, P., Galanina, M., Szczuko, P., Kostek, B., Graff, B., Szplit, D., Budzisz, M., & Narkiewicz, K. (2025). A Comprehensive Polish Medical Speech Dataset for Enhancing Automatic Medical Dictation. Scientific Data, 12(1). https://doi.org/10.1038/s41597-025-05776-1
D, S., S, S. S., S, B. P., D, N. K., & S, V. (2025). A Review of Automatic Speech Recognition Approaches for Bridging Communication Gaps in Clinical Handover. 2025 IEEE 2nd International Conference for Women in Computing (InCoWoCo), 1–7. https://doi.org/10.1109/incowoco68239.2025.11407097
Darmawan, F. A., Mauludin, M. B., & Aditya, C. S. K. (2026). Hybrid Video Transcription Summarization with a BERT-Based Clustering and BART. Jurnal RESTI (Rekayasa Sistem Dan Teknologi Informasi), 9(6), 1439–1450. https://doi.org/10.29207/resti.v9i6.7066
de Margerie-Mellon, C., Duron, L., Fournier, L., Ouakil, L., Soulat, G., & Teixeira, P. G. (2026). Reporting efficiency in diagnostic imaging: Can plug-and-play general-purpose large language models outperform conventional speech recognition? European Radiology. https://doi.org/10.1007/s00330-026-12524-5
Denecke, K., Lopez-Campos, G., Rivera-Romero, O., & Gabarron, E. (2025). The Unexpected Harms of Artificial Intelligence in Healthcare: Reflections on Four Real-World Cases. Healthcare of the Future 2025. https://doi.org/10.3233/shti250219
Dymbe, S., Siniscalchi, S. M., Svendsen, T., & Salvi, G. (2025). Using Cross-Attention for Conversational ASR over the Telephone. Text, Speech, and Dialogue, 394–405. https://doi.org/10.1007/978-3-032-02548-7_33
Earle, R., Leedie, F., Littlewood, R., Nalatu, S., Yusif, S., & Walker, J. L. (2026). Mixed Methods Evaluation of “Cooking Monsters”: An Empowerment-Focussed Aboriginal and Torres Strait Islander Adolescent Nutrition Programme. Journal of Primary Care &Amp; Community Health, 17. https://doi.org/10.1177/21501319261419935
Earnhardt, A. V., Riordan, P. S., Kahlon, C. H., Nwajei, F. I., & McCants, K. M. (2026). Artificial Intelligence in Mental Health. Nursing Clinics of North America, 61(1), 101–111. https://doi.org/10.1016/j.cnur.2025.09.011
Efstathiadis, G., Yadav, V., & Abbas, A. (2025). LLM-based speaker diarization correction: A generalizable approach. Speech Communication, 170, 103224. https://doi.org/10.1016/j.specom.2025.103224
El Hajal, K., Hermann, E., Kulkarni, A., & Magimai.-Doss, M. (2025). Unsupervised Rhythm and Voice Conversion of Dysarthric to Healthy Speech for ASR. 2025 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), 1–5. https://doi.org/10.1109/icasspw65056.2025.11011033
Englander, H., Rolland, B., & Jauffret-Roustide, M. (2025). “Un attracteur de soins”: Bringing People Into Care. Interdisciplinary Health Care Professionals’ Attitudes Toward Opioid Agonist Therapy in France: a Qualitative Study with Implications for the United States. Substance Use &Amp; Addiction Journal, 46(3), 643–653. https://doi.org/10.1177/29767342251324325
Evans, T., & Hogg, J. (2025). NHS England guidance on AI scribes. British Dental Journal, 239(3), 154. https://doi.org/10.1038/s41415-025-9061-0
Faila Nadhifatul Aryza, & Hidayat, S. (2026). Development of Hybrid Feature Based Models for Dysarthric Speech Recognition. International Journal of Online and Biomedical Engineering (iJOE), 22(04). https://doi.org/10.3991/ijoe.v22i04.59849
Flynn, R., & Ragni, A. (2026). Beyond the Utterance: An Empirical Study of Very Long Context Speech Recognition. IEEE Transactions on Audio, Speech and Language Processing, 34, 910–920. https://doi.org/10.1109/taslpro.2026.3658246
Ganet, A. (2025). Compilation d’un corpus oral et numérique en anglais de la mode et de la muséologie : difficultés de transcription et stratégies de correction dans le corpus VidEx. ASp, 88, 253–280. https://doi.org/10.4000/15c2i
Gani, U. A. S., Madankar, A., Shinde, A., Sonwane, A., & Durbade, S. (2025). AI-Associate: A Lightweight Architecture for Conversational Agents. 2025 4th OPJU International Technology Conference (OTCON) on Smart Computing for Innovation and Advancement in Industry 5.0, 1–8. https://doi.org/10.1109/otcon65728.2025.11070569
Ghosh, R., Asaadi, S., Karn, S. K., Ullaskrishnan, U., & Farri, O. (2026). Healthcare in the Age of LLMs. Artificial Intelligence and Large Language Models, 121–153. https://doi.org/10.1201/9781003492252-5
Gijón Flores, Á., Bolaños Peño, C., Llumiguano Solano, H., Fernández-Bermejo Ruiz, J., Jesús Villanueva Molina, F., & Rincón Calle, F. (2026). From Voice to Shell: A SLM-Based Assistant for IoT Maintenance Tasks on the Edge. IEEE Internet of Things Journal, 13(2), 3000–3012. https://doi.org/10.1109/jiot.2025.3632638
Grubert, J., Schmalstieg, D., & Dickhaut, K. (2025). Towards Supporting Literary Studies Using Virtual Reality and Generative Artificial Intelligence. 2025 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), 147–149. https://doi.org/10.1109/vrw66409.2025.00037
Han, Y., Lam, J. C. k., Li, V. O. k., & Cheung, L. Y. L. (2025). An LLM-based Temporal-spatial Data Generation and Fusion Approach for Early Detection of Late Onset Alzheimer’s Disease (LOAD) Stagings Especially in Chinese and English-speaking Populations. Findings of the Association for Computational Linguistics: EMNLP 2025, 14977–14990. https://doi.org/10.18653/v1/2025.findings-emnlp.809
Harvey, E., Kizilcec, R. F., & Koenecke, A. (2025). A Framework for Auditing Chatbots for Dialect-Based Quality-of-Service Harms. Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, 2025–2039. https://doi.org/10.1145/3715275.3732137
Hassanat, A. B., Tarawneh, A. S., Al-khlifeh, E., Almahadin, A. O., Alghamdi, M., Almohammadi, K., Alrashidi, M., Alhasanat, L. A., & Al-Nawafleh, A. H. (2026). Machine Learning-Based Detection of Parkinson’s Disease From Arabic Speech: A Cross-Linguistic Validation Study. Journal of Central Nervous System Disease, 18. https://doi.org/10.1177/11795735261448278
Hidayat, A. (2025). Multi-Label Classification of Indonesian Voice Phishing Conversations: A Comparative Study of XLM-RoBERTa and ELECTRA. Journal of Applied Data Sciences, 6(3), 2177–2191. https://doi.org/10.47738/jads.v6i3.858
Hlongwane, K., Mthethwa, S., & Manqele, L. (2025). Enhancing Diversity in Inclusive Learning Classroom Using OpenAI Whisper Model. 2025 IST-Africa Conference (IST-Africa), 1–9. https://doi.org/10.23919/ist-africa67297.2025.11060520
Ho, P. H., Bălan, D. A., Heylen, D. K. J., & Truong, K. P. (2025). Enhancing Transcripts of Open-Source Automatic Speech Recognition Models Through Fine-Tuning with Laughter and Speech-Laugh. Interspeech 2025, 4513–4517. https://doi.org/10.21437/interspeech.2025-2193
Jha, A., & Gloor, P. A. (2025). Do What You Say—Computing Personal Values Associated with Professions Based on the Words They Use. Algorithms, 18(2), 72. https://doi.org/10.3390/a18020072
John, T., & Möller, A. L. (2024). On-Demand Internationalization for Learning Management System Moodle. HCI International 2024 Posters, 95–102. https://doi.org/10.1007/978-3-031-61953-3_11
Jothieswari, J., & Suguna, S. (2025). Transformer-Based Whisper Classifier for Enhanced Dysarthric Speech Recognition Using UA Speech Dataset. 2025 IEEE International Conference on Contemporary Computing and Communications (InC4), 1–6. https://doi.org/10.1109/inc465408.2025.11256452
K, M. R., M, R. S., K, A., & Indrason, N. (2026). Speech Emotion Recognition Using Deep Learning by Hybridizing CNN-BiLSTM and Attention Mechanism. 2026 IEEE International Conference on Interdisciplinary Approaches in Technology and Management for Social Innovation (IATMSI), 1–6. https://doi.org/10.1109/iatmsi68868.2026.11466131
Kamran, H., Dorrani, A., & Kamran, H. (2026). The Algorithmic Reconfiguration of Qualitative Inquiry: Navigating AI-Driven Efficiency and Interpretive Richness. AI, Society and Digital Transformation, 250–261. https://doi.org/10.1007/978-3-032-13116-4_20
King, E., Yu, H., Vartak, S., Jacob, J., Lee, S., & Julien, C. (2025). Teaching Things To Think: Bootstrapping Local Reasoning for Smart(er) Devices. 2025 IEEE International Conference on Pervasive Computing and Communications (PerCom), 78–88. https://doi.org/10.1109/percom64205.2025.00027
Kumar, S., Tejas, B. N., Hithaish, Budale, R. R., & Kamath, P. R. (2026). An Audio-Visual Speech Separation and Personalized Keyphrase Detection in Noisy Environments. Proceedings of the Third Congress on Control, Robotics, and Mechatronics, 297–308. https://doi.org/10.1007/978-981-96-8126-6_21
Larson, M. (2026). Oral History Encounters AI: An Exploration of Core Principles and Best Practices, Context and Consent. The Oral History Review, 53(1), 93–110. https://doi.org/10.1080/00940798.2026.2625663
LeFevre, G., Hosier, J., Zhou, Y., & Gurbani, V. K. (2025). LLM Selection: Improving ASR Transcript Quality via Zero-Shot Prompting. SoutheastCon 2025, 1440–1445. https://doi.org/10.1109/southeastcon56624.2025.10971586
Li, J., Li, Q., Gong, R., Wang, L., & Wu, S. (2025). Our Collective Voices: The Social and Technical Values of a Grassroots Chinese Stuttered Speech Dataset. Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, 2768–2783. https://doi.org/10.1145/3715275.3732179
Linke, J., Winkler, J., & Schuppler, B. (2025). Context is all you need? Low-resource conversational ASR profits from context, coming from the same or from the other speaker. Interspeech 2025, 3199–3203. https://doi.org/10.21437/interspeech.2025-1824
Litterer, B. R., Jurgens, D., & Card, D. (2025). Mapping the Podcast Ecosystem with the Structured Podcast Research Corpus. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 25132–25154. https://doi.org/10.18653/v1/2025.acl-long.1222
Looi, J. C., Allison, S., Bastiampillai, T., Reutens, S., & Looi, R. C. (2025). Illusions of intelligence, connection and reality: Perils of large-language AI models for people with severe mental illness. Australasian Psychiatry, 34(1), 5–7. https://doi.org/10.1177/10398562251380544
Luchkina, E., Simon, L. R., & Waxman, S. R. (2025). Catching up with iCatcher: Comparing analyses of infant eye tracking based on trained human coders and iCatcher+ automated gaze coding software. Behavior Research Methods, 57(6). https://doi.org/10.3758/s13428-025-02683-6
Ma, Q., Zhang, W., Chen, J., Jia, J., Wang, R., & Yan, D. (2026). DUAP: Disentanglement-Based Universal Adversarial Perturbations for Robust Multilingual Speech Privacy Protection. IEEE Transactions on Information Forensics and Security, 21, 3703–3718. https://doi.org/10.1109/tifs.2026.3671687
Maheshwari, G., Ivanov, D., Johannet, T., & El Haddad, K. (2025). ASR Benchmarking: Need for a More Representative Conversational Dataset. ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1–5. https://doi.org/10.1109/icassp49660.2025.10888906
Małysiak-Mrozek, B., Wojaczek, P., Tokarz, K., Sunderam, V., Mrozek, D., & Lamirel, J.-C. (2025). Automatic Help Summoning Through Speech Analysis on Mobile Devices. Computational Science – ICCS 2025 Workshops, 18–32. https://doi.org/10.1007/978-3-031-97573-8_2
Mansoor, H., Abdullah, U., Adil, S., Jamil, A., Hameed, A. A., & Soleimani, F. (2025). Mitigating Hallucinations in Speech Recognition Systems for Noisy Data. 2025 IEEE 4th International Conference on Computing and Machine Intelligence (ICMI), 1–5. https://doi.org/10.1109/icmi65310.2025.11141067
Massenon, R., Gambo, I., Khan, J. A., Agbonkhese, C., & Alwadain, A. (2025). ”My AI is Lying to Me”: User-reported LLM hallucinations in AI mobile apps reviews. Scientific Reports, 15(1). https://doi.org/10.1038/s41598-025-15416-8
Mawalim, C. O., Okada, S., & Unoki, M. (2024). Are Recent Deep Learning-Based Speech Enhancement Methods Ready to Confront Real-World Noisy Environments? Interspeech 2024, 1735–1739. https://doi.org/10.21437/interspeech.2024-129
McGonigle, E., VanDam, M., Wilkinson, C., & Johnson, K. T. (2024). Benchmarking Automatic Speech Recognition Technology for Natural Language Samples of Children With and Without Developmental Delays. 2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), 1–5. https://doi.org/10.1109/embc53108.2024.10782773
Minamoto, A., Zhang, Z., & Wang, Z. (2025). Solving Language and Culture Barriers on Medical Care: An Inclusive Medical Interpretation Agent-Medylan. Adjunct Proceedings of the 27th International Conference on Mobile Human-Computer Interaction, 1–6. https://doi.org/10.1145/3737821.3748523
Mukmin, A., Adnan, Jalil, A., Pallawabonang, M., Prakasa, E., & Yuyun. (2024). Leveraging the Pre-Trained Whisper Model and Levenshtein Distance for Audio Buginesse Transcription. 2024 beyond Technology Summit on Informatics International Conference (BTS-I2C), 589–594. https://doi.org/10.1109/bts-i2c63534.2024.10942151
N, K., Andanur, P., Udupa E P, P., Airani, S. S., & Dattathreya. (2025). AI-Powered Voice Assistants for Accessible E-Commerce: A Review of ASR, RAG, LLMs and TTS. 2025 5th International Conference on Evolutionary Computing and Mobile Sustainable Networks (ICECMSN), 707–712. https://doi.org/10.1109/icecmsn68058.2025.11383381
Nguyen, T., & Tran, H.-D. (2025). AsyncSwitch: Asynchronous Text-Speech Adaptation for Code-Switched ASR. 2025 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 1–7. https://doi.org/10.1109/asru65441.2025.11434656
Nygren, T., Samuelsson, M., Hansson, P.-O., Efimova, E., & Bachelder, S. (2025). AI Versus Human Feedback in Mixed Reality Simulations: Comparing LLM and Expert Mentoring in Preservice Teacher Education on Controversial Issues. International Journal of Artificial Intelligence in Education, 35(5), 2856–2888. https://doi.org/10.1007/s40593-025-00484-8
O’Connor Russell, S., & Harte, N. (2025). Visual Cues Support Robust Turn-taking Prediction in Noise. Interspeech 2025, 1073–1077. https://doi.org/10.21437/interspeech.2025-668
O’Kane, R., Stonehouse-Smith, D., Ota, L. C. U., Patel, R., Johnson, N., Slipper, C., Seehra, J., Papageorgiou, S. N., & Cobourne, M. T. (2025). Transcription Accuracy of Automatic Speech Recognition for Orthodontic Clinical Records. Journal of Dental Research. https://doi.org/10.1177/00220345251382452
Olagoke, A., Jacobson, L. T., Babajide, O., & Qi, Z. (2026). Building Safe AI Chatbots for Rural Mothers Seeking Breastfeeding Support: Understanding Hallucinations and How to Mitigate Them. Social Sciences, 15(2), 119. https://doi.org/10.3390/socsci15020119
Pan, E., Choi, A. S. G., Ter Hoeve, M., Seto, S., & Koenecke, A. (2025). Analyzing Dialectical Biases in LLMs for Knowledge and Reasoning Benchmarks. Findings of the Association for Computational Linguistics: EMNLP 2025, 20882–20893. https://doi.org/10.18653/v1/2025.findings-emnlp.1139
Pan, L., Jiang, C., Hou, G., & Gao, Y. (2025). Teochew-Wild: The First In-the-wild Teochew Dataset with Orthographic Annotations. 2025 IEEE International Conference on Multimedia and Expo (ICME), 1–6. https://doi.org/10.1109/icme59968.2025.11209855
Pande, A., & Mishra, D. (2024). Assessment of Pepper Robot’s Speech Recognition System through the Lens of Machine Learning. Biomimetics, 9(7), 391. https://doi.org/10.3390/biomimetics9070391
Park, H. I., Solon, M., & Lee, K. (2025). Understanding proficiency assessment practices in SLA research. Studies in Second Language Acquisition, 47(5), 1205–1229. https://doi.org/10.1017/s0272263125101058
Pengsiri, P., Malang, C., & Pongpatcharatorntep, D. (2026). Text Analytics for Identifying the Competitiveness of Northern Thai SMEs’ Products. 2026 Joint International Conference on Digital Arts, Media and Technology with ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunication Engineering (ECTI DAMT &Amp;Amp; NCON), 466–471. https://doi.org/10.1109/ectidamtncon67592.2026.11460023
Pisal, T., Hajare, R., Verma, P., Gote, P. M., Jiet, M., & Chaudhri, S. N. (2025). AI-Driven Transcription and Analysis for Medical Conversations. 2025 International Conference on Machine Learning and Autonomous Systems (ICMLAS), 1228–1234. https://doi.org/10.1109/icmlas64557.2025.10969001
Prajwal, T. S., Desu, L., Kumari, N., & Kumar, R. (2025). Content Moderation and File Anonymization using Agentic AI. 2025 5th International Conference on Electrical, Computer and Energy Technologies (ICECET), 1–6. https://doi.org/10.1109/icecet63943.2025.11472200
Prasad, C., Swamy Rao, V. G., J, G., & Naidu, R. C. A. (2026). An ASR Transformer-Based Model for Kannada Speech-to-Text Transcription. Journal of Artificial Intelligence and Technology. https://doi.org/10.37965/jait.2026.0935
Prem, D., Raimond, K., & Jeyabose, A. (2025). Investigating the Impact of Feature Extraction Techniques for Classification and Synthesis of Dysarthric Speech. Circuits, Systems, and Signal Processing. https://doi.org/10.1007/s00034-025-03366-5
R, V., D, H., & Anand, L. D. V. (2024). Leveraging OpenAI Whisper Model to Improve Speech Recognition for Dysarthric Individuals. 2024 Asia Pacific Conference on Innovation in Technology (APCIT), 1–5. https://doi.org/10.1109/apcit62007.2024.10673628
Rangappa, P., Zuluaga-Gomez, J., Madikeri, S., Carofilis, A., Prakash, J., Burdisso, S., Kumar, S., Villatoro-Tello, E., Nigmatulina, I., Motlicek, P., Pandia, K., & Ganapathiraju, A. (2025). Speech Data Selection for Efficient ASR Fine-Tuning using Domain Classifier and Pseudo-Label Filtering. ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1–5. https://doi.org/10.1109/icassp49660.2025.10888138
Ranjith, A., G, J. Lal., & B, P. (2025). Robust Dysarthria Detection and Severity Classification Framework Using Multifeature Speech Representations and Deep Learning Models. 2025 IEEE 22nd India Council International Conference (INDICON), 1–6. https://doi.org/10.1109/indicon68490.2025.11392854
Rao, N., O’Riordan, S., & Coulis, J. (2025). AI and labor: Captioning library audiovisual content with Whisper. IFLA Journal, 51(3), 803–813. https://doi.org/10.1177/03400352241310534
Rastall, D. P. W., & Rehman, M. (2025). Why Clinical Trials Will Fail to Ensure Safe AI. Journal of Medical Systems, 49(1). https://doi.org/10.1007/s10916-025-02231-x
Reutens, S., Dandolo, C., Looi, R. C. H., Karystianis, G. C., & Looi, J. C. L. (2024). The uses and misuses of artificial intelligence in psychiatry: Promises and challenges. Australasian Psychiatry, 33(1), 9–11. https://doi.org/10.1177/10398562241280348
Rixen, J., & Renz, M. (2025). Efficient Speech Separation with Differencing. Ecai 2025. https://doi.org/10.3233/faia251307
Rodger, D., & O’Connor, S. (2025). Using artificial intelligence in health research. Evidence Based Nursing, 28(4), 203–205. https://doi.org/10.1136/ebnurs-2025-104287
Rohanian, M., Hüppi, R., Nooralahzadeh, F., Dannecker, N., Pauli, Y., Surbeck, W., Sommer, I., Hinzen, W., Langer, N., Krauthammer, M., & Homan, P. (2026). Uncertainty modeling in multimodal speech analysis across the psychosis spectrum. Npj Digital Medicine, 9(1). https://doi.org/10.1038/s41746-025-02309-3
Rosas-Smith, J., Bartelds, M., Huang, R., García-Perera, L. P., Livescu, K., Jurafsky, D., & Field, A. (2025). Constructing Datasets From Public Police Body Camera Footage. ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1–5. https://doi.org/10.1109/icassp49660.2025.10888621
Russell, S. O., & Harte, N. (2025). Visual Cues Enhance Predictive Turn-Taking for Two-Party Human Interaction. Findings of the Association for Computational Linguistics: ACL 2025, 209–221. https://doi.org/10.18653/v1/2025.findings-acl.12
Şahin, M. F., Topkaç, E. C., Doğan, Ç., Şeramet, S., Tuncer, F. B., Köroğlu, M. S., Orbeği, O., & Yazici, C. M. (2025). AI-assisted transcription of YouTube videos on penile enlargement: analysis of their text quality and readability. Sexual Medicine, 13(2). https://doi.org/10.1093/sexmed/qfaf023
Saranya, D. S., Anirudh, D., Reddy, K. P., Kumar, N. S. S. S. G., & Jabbar, M. A. (2025). TalkGenie: Intent and Sentiment-Aware Multilingual Chatbot. 2025 International Conference on Intelligent Communication Networks and Computational Techniques (ICICNCT), 1–6. https://doi.org/10.1109/icicnct66124.2025.11232647
Schock, B., Kuraner, S. E., Westphal, M., & Bonanno, G. A. (2025). How “algospeak” is changing online discourse on suicide and self-harm: A pilot study. Traumatology. https://doi.org/10.1037/trm0000581
Shailja, S., Williams, T., & Pandey, A. Self-efficacy of high school students after an AI-focused pre-college program: A two year impact study (Fundamental). 2025 ASEE Annual Conference &Amp; Exposition Proceedings. https://doi.org/10.18260/1-2--57638
Shamsian, A., Navon, A., Glazer, N., Hetz, G., & Keshet, J. (2024). Keyword-Guided Adaptation of Automatic Speech Recognition. Interspeech 2024, 732–736. https://doi.org/10.21437/interspeech.2024-391
Shao, A. (2025). New sources of inaccuracy? A conceptual framework for studying AI hallucinations. Harvard Kennedy School Misinformation Review. https://doi.org/10.37016/mr-2020-182
Sharon, T. (2025). Technosolutionism and the empathetic medical chatbot. AI &Amp; SOCIETY, 41(1), 289–306. https://doi.org/10.1007/s00146-025-02441-4
Sharp, K., Ouellette, R. R., Singh, R. S. R., DeVito, E. E., Kamdar, N., de la Noval, A., Murthy, D., & Kong, G. (2025). Generative artificial intelligence and machine learning methods to screen social media content. PeerJ Computer Science, 11, e2710. https://doi.org/10.7717/peerj-cs.2710
Sherstinova, T. Y., & Petrova, I. (2024). ESC Corpus of Spoken Russian: Everyday Student Conversations Captured Through Continuous Speech Recording in Natural Communicative Environments. Speech and Computer, 151–162. https://doi.org/10.1007/978-3-031-77961-9_11
Shubash, J., Athmika, S., Deekshitha, S., Meghana, K. N., & Varsha, S. (2025). CareLoop – AI-Driven Approach for Advancing Efficiency, Accuracy, and Accessibility in Oral Healthcare Systems. 2025 Third International Conference on Emerging Applications of Material Science and Technology (ICEAMST), 1305–1309. https://doi.org/10.1109/iceamst67459.2025.11336036
Sloane, M., Schellmann, H., Mei, K. X., Choi, A. S. G., & Koenecke, A. (2026). The case for stakeholder-driven AI auditing in automatic speech recognition. Nature Machine Intelligence, 8(4), 493–494. https://doi.org/10.1038/s42256-026-01207-x
Sohrabi, R. (2026). When AI fails to listen: convergent failure patterns across speech impairments and low-resource speech in ASR. AI &Amp; SOCIETY. https://doi.org/10.1007/s00146-026-03073-y
Sridhar, C., & Wu, S. (2025). J-j-j-just Stutter: Benchmarking Whisper’s Performance Disparities on Different Stuttering Patterns. Interspeech 2025, 3753–3757. https://doi.org/10.21437/interspeech.2025-2700
Srivastava, M., Ferro, M., Pirrelli, V., & Coro, G. (2026). Enhancing token boundary detection in disfluent speech. Intelligent Systems with Applications, 29, 200614. https://doi.org/10.1016/j.iswa.2025.200614
Steinert, P., Wagenpfeil, S., Frommholz, I., & Hemmje, M. L. (2026). A Reference Model for the Analysis and Indexing of Metaverse Recordings for Information Retrieval. Big Data and Cognitive Computing, 10(3), 85. https://doi.org/10.3390/bdcc10030085
Stoykova, R., Porter, K., & Beka, T. (2024). The AI Act in a law enforcement context: The case of automatic speech recognition for transcribing investigative interviews. Forensic Science International: Synergy, 9, 100563. https://doi.org/10.1016/j.fsisyn.2024.100563
Susaiyah, A., & Sidorova, N. (2025). Zero-Shot Approaches for the Extraction of Event Logs from Medical Notes. Research Challenges in Information Science, 435–451. https://doi.org/10.1007/978-3-031-92474-3_26
Tan, T., Chen, X., Le, X., Fan, W., Xia, X., Huang, C., & Lu, J. (2025). CBA-Whisper: Curriculum Learning-Based AdaLoRA Fine-Tuning on Whisper for Low-Resource Dysarthric Speech Recognition. Interspeech 2025, 3309–3313. https://doi.org/10.21437/interspeech.2025-1705
Taneja, D., & Bhatt, S. (2025). Enhancing Hindi Speech Recognition Using Regularization Techniques. 2025 7th International Conference on Artificial Intelligence and Speech Technology (AIST), 1–6. https://doi.org/10.1109/aist68591.2025.11441569
Taubitz, F.-S., Sehn, L. H. A., & Alpers, G. W. (2025). Language Model, bitte zum Diktat: Transkription, Sprecher*innenzuordnung und datenschutzkonforme Verarbeitung von Therapiegesprächen mit KI. Verhaltenstherapie, 1–18. https://doi.org/10.1159/000549546
Temel, M. H., Erden, Y., & Bağcıer, F. (2024). Assessing Patients Perception: Analyzing the Quality, Reliability, Comprehensibility, and the Mentioned Medical Concepts of Traumatic Brain Injury Videos on YouTube. World Neurosurgery, 185, e907–e914. https://doi.org/10.1016/j.wneu.2024.02.150
Tolle, H., Castro, M. d. M., Wachinger, J., Putri, A. Z., Kempf, D., Denkinger, C. M., & McMahon, S. A. (2024). From voice to ink (Vink): development and assessment of an automated, free-of-charge transcription tool. BMC Research Notes, 17(1). https://doi.org/10.1186/s13104-024-06749-0
Trabelsi, A., Werey, L., Warichet, S., & Helbert, E. (2024). Is Noise Reduction Improving Open-Source ASR Transcription Engines Quality? Proceedings of the 16th International Conference on Agents and Artificial Intelligence, 1221–1228. https://doi.org/10.5220/0012457100003636
Ubur, S. D., Adewale, S., Chandrashekar, N. D., Akli, E. K., & Gracanin, D. (2025). Interpretive Caption: Real-Time Vocal Emotion Cues for DHH Users. Proceedings of the 27th International ACM SIGACCESS Conference on Computers and Accessibility, 1–5. https://doi.org/10.1145/3663547.3759697
Viola, T. W., de Carvalho, M. T., Padoin, R. C. P. K., Kampff, A. J. C., & Padoin, A. V. (2025). Evaluation using artificial intelligence shows post pandemic differences in oral reading fluency between Brazilian public and private school students. Scientific Reports, 15(1). https://doi.org/10.1038/s41598-025-15644-y
Waheed, A., Atwany, H., Singh, R., & Raj, B. (2025). On the Robust Approximation of ASR Metrics. Findings of the Association for Computational Linguistics: ACL 2025, 23119–23146. https://doi.org/10.18653/v1/2025.findings-acl.1187
Wang, Y., Alhmoud, A., Alsahly, S., Alqurishi, M., & Ravanelli, M. (2025). Calm-Whisper: Reduce Whisper Hallucination On Non-Speech By Calming Crazy Heads Down. Interspeech 2025, 3414–3418. https://doi.org/10.21437/interspeech.2025-201
Weilinghoff, A. (2025). Transcribing Diverse Voices: Using Whisper for ICE corpora. Interspeech 2025, 3359–3363. https://doi.org/10.21437/interspeech.2025-1980
Wepner, S., Eckert, L., Kubin, G., & Schuppler, B. (2025). What the Filler? Both ASR Systems and Humans Struggle More With Other Kinds of Disfluencies Than With Filler Particles. Interspeech 2025, 2325–2329. https://doi.org/10.21437/interspeech.2025-757
Wolfartsberger, J., & Niedermayr, D. (2025). Breaking the Code Barrier: Analyzing the Effectiveness of LLMs in Natural Language Interfaces for Collaborative Robotics. 2025 6th International Conference on Artificial Intelligence, Robotics and Control (AIRC), 274–280. https://doi.org/10.1109/airc64931.2025.11077511
Woo, B. F. Y., Song, J., Middleton, E., Fijačko, N., & Cato, K. (2025). Teaching Critical Thinking in the Age of AI: Safeguarding Clinical Reasoning in Healthcare Documentation. International Nursing Review, 72(3). https://doi.org/10.1111/inr.70102
Wu, C., Pan, Y., Wu, H., & Ning, L. (2025). Integrating Speech Recognition into Intelligent Information Systems: From Statistical Models to Deep Learning. Informatics, 12(4), 107. https://doi.org/10.3390/informatics12040107
Wu, S., Wenzel, K., Li, J., Li, Q., Pradhan, A., Kushalnagar, R., Lea, C., Koenecke, A., Vogler, C., Hasegawa-Johnson, M., Su, N. M., & Bernstein Ratner, N. (2025). Speech AI for All: Promoting Accessibility, Fairness, Inclusivity, and Equity. Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, 1–6. https://doi.org/10.1145/3706599.3706746
Wurm, B. (2026). Managing Digital Trace Data Research Projects. Digital Trace Data Research in Information Systems, 3–21. https://doi.org/10.1007/978-3-032-05497-5_1
Yasu Bharathi, V. R., K, P., Madasamy, K. S., Goldwin, K. R., Elangovan, A., & Kumar, M. V. (2025). Edge Deployed Speech to Text Models for Real Time Classroom Feedback in Interactive Linguistics Pronunciation Labs. 2025 2nd International Conference on Artificial Intelligence and Knowledge Discovery in Concurrent Engineering (ICECONF), 1–7. https://doi.org/10.1109/iceconf65644.2025.11379572
Ye, Z., Lian, J., Gupta, A., Zhou, X., Li, H., Patel, K., Park, H. J., Zhou, D., Guo, C., Li, S., Wang, S., Zhou, I., Cho, C. J., Ezzes, Z., Vonk, J. M. J., Morin, B. T., Bogley, R., Wauters, L., Miller, Z. A., et al. (2025). LCS-CTC: Leveraging Soft Alignments to Enhance Phonetic Transcription Robustness. 2025 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 1–8. https://doi.org/10.1109/asru65441.2025.11434691
Yue, Z., Loweimi, E., Cvetkovic, Z., Barker, J., & Christensen, H. (2026). Raw acoustic-articulatory multimodal dysarthric speech recognition. Computer Speech &Amp; Language, 95, 101839. https://doi.org/10.1016/j.csl.2025.101839
Zarco-Alpuente, A., Álvarez, O., Castillo, I., & Samper-García, P. (2026). Digital disconnection in adolescent sport: A reflexive thematic analysis of athletes’ experiences. Psychology of Sport and Exercise, 85, 103098. https://doi.org/10.1016/j.psychsport.2026.103098
Zhang, L., Wu, S., & Wang, Z. (2025). LoRA-INT8 Whisper: A Low-Cost Cantonese Speech Recognition Framework for Edge Devices. Sensors, 25(17), 5404. https://doi.org/10.3390/s25175404
Zhang, S., Parcollet, T., Van Dalen, R., & Bhattacharya, S. (2025). Benchmarking Rotary Position Embeddings for Automatic Speech Recognition. 2025 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 1–7. https://doi.org/10.1109/asru65441.2025.11434788
Zhang, S., Xu, J., & Alvero, A. (2025). Generative AI Meets Open-Ended Survey Responses: Research Participant Use of AI and Homogenization. Sociological Methods &Amp; Research, 54(3), 1197–1242. https://doi.org/10.1177/00491241251327130
Zhang, Y., De Valck, T., & Scharenborg, O. (2026). Speech recognition performance disparities between Dutch diverse speaker groups. Phonetica. https://doi.org/10.1515/phon-2025-0061
Zhang, Y., Yu, S., & Lai, J. (2025). Efficient Deployment of Large Speech Recognition Models on GPU. 2025 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 1–4. https://doi.org/10.1109/asru65441.2025.11434664
Zhao, R., Choi, A. S. G., Koenecke, A., & Rameau, A. (2024). Quantification of Automatic Speech Recognition System Performance on d/Deaf and Hard of Hearing Speech. The Laryngoscope. https://doi.org/10.1002/lary.31713
Zhao, X., & Van Hamme, H. (2025). Refining Transcripts with TV Subtitles by Prompt-Based Weakly Supervised Training of ASR. 2025 33rd European Signal Processing Conference (EUSIPCO), 346–350. https://doi.org/10.23919/eusipco63237.2025.11226307
Zhiyenbayev, A., Abdrakhmanov, R., Varol, H. A., & Yazici, A. (2025). Multi-Modal Vision and Language Models for Real-Time Emergency Response. 2025 IEEE 37th International Conference on Tools with Artificial Intelligence (ICTAI), 1199–1206. https://doi.org/10.1109/ictai66417.2025.00175
Ziegler, M., Lothian, S., O’Neill, B., Anderson, R., & Ota, Y. (2025). AI language models could both help and harm equity in marine policymaking. Npj Ocean Sustainability, 4(1). https://doi.org/10.1038/s44183-025-00132-7
Zusag, M., Wagner, L., & Thallinger, B. (2024). CrisperWhisper: Accurate Timestamps on Verbatim Speech Transcriptions. Interspeech 2024, 1265–1269. https://doi.org/10.21437/interspeech.2024-731
Barnes, C. A., & Najafi, B. (2025). The Precision Aging® Network: Creating a Roadmap for Healthy Brain Aging. Gerontology, 1–7. https://doi.org/10.1159/000548488
Barrett, T. S., Wynn, C. J., Eijk, L., Tetzloff, K. A., & Borrie, S. A. (2025). Autoscribe: An automated tool for creating transcribed TextGrids from audio-recorded conversations. Behavior Research Methods, 57(12). https://doi.org/10.3758/s13428-025-02850-9
Cao, Y. (2025). Performance Evaluation of Whisper-Series Speech Transcription Models on Raspberry Pi. Proceedings of the Tenth ACM/IEEE Symposium on Edge Computing, 1–7. https://doi.org/10.1145/3769102.3774244
Kaplan, D. M., Alvarez, S. J. A., Palitsky, R., Choi, H., Clifford, G. D., Crozier, M., Dunlop, B. W., Grant, G. H., Greenleaf, M. N., Johnson, L. M., Maples-Keller, J., Levin-Aspenson, H. F., Mascaro, J. S., McDowall, A., Pozzo, N. S., Raison, C. L., Zarrabi, A. J., Rothbaum, B. O., & Lam, W. A. (2025). Fabla: A voice-based ecological assessment method for securely collecting spoken responses to researcher questions. Behavior Research Methods, 57(9). https://doi.org/10.3758/s13428-025-02777-1
Min, S., Yeum, T.-S., Shin, D., Rhee, S. J., Lee, H., Lee, H.-S., Park, S., Lee, J., & Ahn, Y. M. (2025). Automated Speech Analysis for Screening and Monitoring Bipolar Depression: Machine Learning Model Development and Interpretation Study. JMIR Medical Informatics, 13, e79093. https://doi.org/10.2196/79093
Naffah, A., Pfeifer, V. A., & Mehl, M. R. (2025). Spoken Language Analysis in Aging Research: The Validity of AI-Generated Speech to Text Using OpenAI’s Whisper. Gerontology, 71(5), 417–424. https://doi.org/10.1159/000545244
Wenzel, K., Pradhan, A., Teleki, M., Weinberg, T. M., Netzorg, R., Hillary Zisk, A., Choi, A. S. G., Li, J., Kushalnagar, R., Lea, C., Glasser, A., Vogler, C., Brown, L. X. M. Z., Ratner, N. B., Koenecke, A., Nakamura, K., & Wu, S. (2026). Speech AI for All: The What, How, and Who of Measurement. Proceedings of the Extended Abstracts of the 2026 CHI Conference on Human Factors in Computing Systems, 1–6. https://doi.org/10.1145/3772363.3778768
Cifliku, B., & Heuer, H. (2026). They Think AI Can Do More Than It Actually Can: Practices, Challenges, & Opportunities of AI-Supported Reporting In Local Journalism. Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems, 1–20. https://doi.org/10.1145/3772318.3791130
Tang, X., Li, J., & Wu, S. (2026). Disability-First AI Dataset Annotation: Co-designing Stuttered Speech Annotation Guidelines with People Who Stutter. Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems, 1–22. https://doi.org/10.1145/3772318.3790405
Burger, K., & White, L. (2026). Advancing Smart OR stewardship: GenAI literacy for Soft OR practitioners. Journal of the Operational Research Society, 1–16. https://doi.org/10.1080/01605682.2026.2672123
Cheng, A., Konova, A. B., Powers, A., Corlett, P., Levy, I., Gu, X., Huys, Q., Pushkarskaya, H., Fineberg, S., Hauser, T., Chase, H. W., Bzdok, D., Harpaz-Rotem, I., Babuscio, T., Nichols, L., Zhao, Y., Sharma, M., Meeker, D., Xu, H., et al. (2026). Threading the Needle: Practical Considerations for Merging Theory-Driven Computational Psychiatry With Data-Driven Analytics to Enhance Precision Health at Scale. Biological Psychiatry: Cognitive Neuroscience and Neuroimaging. https://doi.org/10.1016/j.bpsc.2026.02.009
Sherstinova, T. Yu., Melnik, A. G., Petrova, I. A., Melkozerova, V. I., & Chepovetskaya, S. V. (2025). “Okie dokie, here’s the no-cap truth!”: Everyday Russian Youth Speech in Corpus Representation (Structure and Application of the ESC Sound Corpus). Computational Linguistics and Intellectual Technologies. https://doi.org/10.28995/2075-7182-2025-23-331-344
Alabbad, M., & Alhoshan, W. (2026). Automatic Speech Recognition in Healthcare in the Post-LLM Era: A Scoping Review. Healthcare, 14(10), 1333. https://doi.org/10.3390/healthcare14101333
Kamahori, K., Kasai, J., Kojima, N., & Kasikci, B. (2025). LiteASR: Efficient Automatic Speech Recognition with Low-Rank Approximation. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 3430–3442. https://doi.org/10.18653/v1/2025.emnlp-main.169
Liang, S., Ballier, N., Levow, G.-A., & Wright, R. (2025). Beyond WER: Probing Whisper’s Sub‐token Decoder Across Diverse Language Resource Levels. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 31225–31235. https://doi.org/10.18653/v1/2025.emnlp-main.1591
Raes, R., Lensink, S. E., & Pechenizkiy, M. (2026). Everyone Deserves their Voice to Be Heard: Analyzing Predictive Gender Bias in ASR Models Applied to Dutch Speech Data. Machine Learning and Principles and Practice of Knowledge Discovery in Databases, 19–34. https://doi.org/10.1007/978-3-032-25308-8_2
Awobade, B., Sanni, M., Abdullahi, T., Okocha, C., Ezema, K., Kayande, D. D., Ismaila, L. E., Olatunji, T., & Katuka, G. A. (2026). AfriVox: Probing Multilingual and Accent Robustness of Speech LLMs. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), 2672–2690. https://doi.org/10.18653/v1/2026.eacl-long.122
Kalibatiene, D., & Jancevičius, J. (2026). Comparative Evaluation of Automatic Speech Recognition Models for Multi-accent University Admissions Interview Transcription. Business Information Systems, 263–276. https://doi.org/10.1007/978-3-032-26363-6_20
P, M., Vivek, S., S, R., & Radhika, S. (2026). Graph-Based Hierarchical Multi-Level Framework for Audio Caption Generation. 2026 International Conference on Wireless Communications Signal Processing and Networking (WiSPNET), 1–6. https://doi.org/10.1109/wispnet69615.2026.11489442
Nassehi, D., Hetlevik, Ø., & Breivold, J. (2026). Exploring AI scribes in Norwegian general practice: a qualitative individual interview study. Scandinavian Journal of Primary Health Care, 44(1). https://doi.org/10.1080/02813432.2026.2681143
Nagaraj, P., Uma, P. S., Natchiar, S. U., Prabakaran, R. P., Muralidharan, B., & Virumapandi, V. (2026). A Framework on Automatic Speech Recognition Systems Using Natural Language Processing. 2026 International Conference on Future and Advanced Computing Technologies (ICFACT), 1–6. https://doi.org/10.1109/icfact66887.2026.11518405
Tan, S. M. X., Lieu, M. Y., Kai, J., Yang, Z., KK, L., Lwin, M. O., Lee, J., & Goh, W. W. B. (2025). Predicting Ultra-High Risk Outcomes Using Linguistic and Acoustic Measures From High-Risk Social Challenge Recordings: mHealth Longitudinal Cohort Exploratory Study. JMIR Formative Research, 9, e75960–e75960. https://doi.org/10.2196/75960
Rajanikanth, K. N., Iyer, D., Kasyap, A., & Doreswamy, S. (2026). BEST: Blockchain And AI-Enabled EHR System For Ambulatory Care. 2026 International Conference on Artificial Intelligence and Data Engineering (AIDE), 348–353. https://doi.org/10.1109/aide69088.2026.11544799
Bao, G., & Lu, J. (2026). Propositional Density in EFL Retellings: Relative Contributions of Proficiency, Speech Rate, Lexical Diversity, and Mean Dependency Distance. International Journal of Applied Linguistics. https://doi.org/10.1111/ijal.70277
Alarcon-Garrido, D., Ortiz-Perez, D., Mulero-Pérez, D., Saval-Cillero, L., Garcia-Rodriguez, J., & Vizcaya-Moreno, M. F. (2026). Automated Multi-Protocol Assessment for Mild Cognitive Impairment Using a Mobile Health Application. Soft Computing Models in Industrial and Environmental Applications, 586–595. https://doi.org/10.1007/978-3-032-29254-4_47
Piazzesi, C., & Blais, M. (2026). What Does it Mean to be “Romantic”? Young Canadian Adults’ Conception of Romance and Romantic Gestures. Youth and Globalization, 1–29. https://doi.org/10.1163/25895745-bja10058