2025
Scaling systematic reviews: A solo researcher's workflow with Gemini
Conducting systematic literature reviews is traditionally a laborious, manual process involving the extraction of distinct data points from hundreds of academic papers, but this presentation introduces a structured, multi-tool workflow using the Scopus API, NotebookLM and Gemini to automate and enhance this task. By employing a pipeline that includes batch processing PDFs in NotebookLM to prevent data omissions and using Gemini for high-level synthesis, the workflow saves an estimated 30+ hours of manual extraction per review and allows sole researchers to tackle large-scale projects previously requiring teams. Validated by emerging research and peer comparison, this approach democratises access to large-scale reviews, though it necessitates a shift in researcher responsibility toward rigorous prompt engineering and 'human-in-the-loop' validation to ensure accuracy and avoid model drift.
Unpacking ERP responses in artificial language learning
Third language acquisition often involves morphosyntactic transfer from previously acquired languages. Research suggests that crosslinguistic influence follows systematic patterns, with attention playing a role in selecting the source of transfer. This study investigates morphosyntactic transfer longitudinally using artificial languages distributed between groups in two sites: Norway (Mini-Norwegian and Mini-English) and Spain (Mini-Spanish and Mini-English).
The study consists of six sessions. Session 1 assesses attention-related executive functions and language history. Session 2 begins with resting-state electroencephalography (EEG) to measure attentional skills, followed by training on gender agreement (present in Norwegian and Spanish). Sessions 3 and 4 introduce differential object marking (present in Spanish) and verb-object agreement (absent from all three languages), respectively. Each session includes vocabulary pre-training, grammar training, a behavioural test, and an EEG experiment measuring event-related potentials (ERPs) in response to grammatical violations in a grammaticality judgement task. Session 5 reassesses cognitive measures, and Session 6, after four months, tests retention of all grammatical properties.
This presentation will focus on preliminary results with a methodological emphasis. We will first examine accuracy in the grammaticality judgements, which was generally high, before analysing a consistent P600-like effect associated with a control violation involving misplaced definite articles (e.g., jestreet), relative to a grammatical condition (e.g., je street). This effect likely reflects increased attentional demands during syntactic processing. Notably, this control effect is observed across artificial languages, sessions and brain regions (with greater strength in medial and posterior regions), providing a reference point for evaluating the ERPs associated with the grammatical properties of interest. After demonstrating and discussing this comparison, forthcoming analyses will be outlined, and feedback will be welcome.
The study consists of six sessions. Session 1 assesses attention-related executive functions and language history. Session 2 begins with resting-state electroencephalography (EEG) to measure attentional skills, followed by training on gender agreement (present in Norwegian and Spanish). Sessions 3 and 4 introduce differential object marking (present in Spanish) and verb-object agreement (absent from all three languages), respectively. Each session includes vocabulary pre-training, grammar training, a behavioural test, and an EEG experiment measuring event-related potentials (ERPs) in response to grammatical violations in a grammaticality judgement task. Session 5 reassesses cognitive measures, and Session 6, after four months, tests retention of all grammatical properties.
This presentation will focus on preliminary results with a methodological emphasis. We will first examine accuracy in the grammaticality judgements, which was generally high, before analysing a consistent P600-like effect associated with a control violation involving misplaced definite articles (e.g., jestreet), relative to a grammatical condition (e.g., je street). This effect likely reflects increased attentional demands during syntactic processing. Notably, this control effect is observed across artificial languages, sessions and brain regions (with greater strength in medial and posterior regions), providing a reference point for evaluating the ERPs associated with the grammatical properties of interest. After demonstrating and discussing this comparison, forthcoming analyses will be outlined, and feedback will be welcome.
2024
Smart starts: Cognitive differences predict prior knowledge involvement in language learning
Unlike children acquiring their first language (L1), L2/Ln learners can draw on existing grammatical knowledge to ease the task, at least for those properties where the grammars align. This means that, in addition to statistical learning, there might be a substantial role for individual differences in cognitive processes necessary to identify, recruit and deploy this prior knowledge—e.g., procedural memory, working memory (WM), inhibitory control. In this study, we measured these individual differences through an SRT task, a digit-span, and a Stroop task, at the onset of a longitudinal artificial language (AL) learning paradigm. Grammatical and lexical similarity between the ALs and previous languages (Norwegian-English or Spanish-English) were systematically manipulated. Behavioral measures of sensitivity to grammatical violations in the AL were collected after each training session (three total). Results suggest that the ability to capitalize on prior knowledge is significantly modulated by individual differences in procedural memory, WM and inhibitory control.
Making research materials Findable, Accessible, Interoperable and Reusable
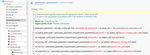
To err is human, but when it comes to creating research materials, mistakes can be reduced by sharing more of our work and by using some helpful tools. For instance, we can make our research materials FAIRer—that is, more Findable, Accessible, Interoperable and Reusable (Wilkinson et al., 2016). These practices facilitate the reproducibility, revision, modification and expansion of research materials, by the creators themselves and by other researchers, at any point in time, which is convenient due to the vital importance of methods in experimental research (Barsalou, 2019). In the current presentation, we describe how documentation practices and open-source software (namely, R and OpenSesame) were used to prepare materials for a study in multilingualism using artificial languages, and comprising several sessions and several grammatical properties. So far, the creation of artificial languages in similar studies has not generally displayed an extensive use of FAIR practices (Cross et al., 2021; González Alonso et al., 2020; Mitrofanova et al., 2023; Morgan-Short et al., 2012; Pereira Soares et al., 2022). In our current study, the stimuli were prepared in R using a modular framework that consisted of interoperable components (Snippet 1). The modularity of this method facilitates the expansion of the materials within the same languages and to other languages. Specifically, the minimal components of each language were contained in a base file in the ‘stimulus_preparation’ folder. Furthermore, for the creation of the final stimuli, several controls were exerted to prevent spurious effects. For instance, gender and number were counterbalanced across experimental conditions, words were rotated across grammatical properties and sessions, and frequency of occurrence was controlled (Snippet 2). The final stimuli can be recreated using the script 'compile_all_stimuli.R', and the resulting stimuli are saved to the 'session_materials' folder. Furthermore, the final stimuli were presented using OpenSesame, which is a free-of-charge software supporting experiments in the social sciences. We describe the implementation of several complex sessions in OpenSesame, which involved the use of conditions for controlling the engagement of certain items. Last, we describe a custom script in OpenSesame that enables the measurement of event-related potentials by time-locking electroencephalographic measures to the onset of specific stimuli. In conclusion, the materials of the current study are accessible, and the workflow is reproducible. As a result, the final materials are testable, modifiable and expandable, improving long-term efficiency.
Investigating language learning and morphosyntactic transfer longitudinally using artificial languages
The acquisition of a third language (L3) often involves the transfer of morphosyntactic structures from the first language and/or the second language to the developing L3 grammar, allowing the recycling of previously acquired knowledge (Rothman et al., 2015). Under the assumption that this crosslinguistic influence is somewhat systematic, much research has investigated the mechanisms involved in selecting a source of transfer given various (competing) options. The use of artificial languages (AL) has allowed researchers to investigate this process from the very onset of L3 acquisition, with some initial findings suggesting a facilitative role of attention prior to the selection of a source of transfer (González Alonso et al., 2020; Pereira Soares et al., 2022). The current study examines morphosyntactic transfer longitudinally in two sites. In Norway, participants were randomly assigned to training and testing in Mini-Norwegian or Mini-English, the former AL being typologically closer to Norwegian. In Spain, Mini-Spanish and Mini-English were used. The study comprises six sessions. Session 1 consists of an assessment of attention-related executive functions and a language history questionnaire. A week later, Session 2 begins with a resting-state electroencephalographic measurement, which captures attention skills (Rogala et al., 2020). We hypothesise that attention facilitates learning and transfers. The rest of the session is devoted to the grammatical property of gender agreement (part of Norwegian and Spanish grammars). A week later, Session 3 adds the property of differential object marking (part of Spanish grammar, absent in the other two languages). A week later, Session 4 adds the property of verb-object agreement (absent from the English, Norwegian and Spanish grammars). The grammar part of Sessions 2, 3 and 4 consists of a vocabulary pre-training, a training in the new grammatical property, a behavioural test and an electroencephalography experiment measuring event-related potentials (ERPs) in response to grammatical and ungrammatical instances of each property. A week after Session 4, Session 5 provides a retest of the cognitive battery from Session 1. Last, after a consolidation period of four months, all grammatical properties are retested in Session 6 (see Morgan-Short et al., 2012). Our analyses delve into language learning, morphosyntactic transfer, and their associations with executive functions longitudinally.
2021
Linguistic and embodied systems in conceptual processing: Variation across individuals and items
The first study (Bernabeu et al., 2021) will merge existing datasets (Lynott et al., 2020; Pexman et al., 2017; Pexman & Yap, 2018; Wingfield & Connell, 2019). The second study will collect novel data to investigate questions such as the unique roles of vocabulary size, sensorimotor experience and attentional control.
Towards reproducibility and maximally-open data
A talk on reproducibility and maximally-open data in research, presented at the 2021 Open Scholarship Prize Competition, Open Scholarship Community Galway.
2020
Mixed-effects models in R and a new tool for data simulation
In this talk, I will look over the rationale for LMEMs, and demonstrate how to fit them in R (Brauer & Curtin, 2018; Luke, 2017). Challenges will also be covered. For instance, when using the widely-accepted 'maximal' approach, based on fitting all possible random effects for each fixed effect, models sometimes fail to find a solution, or 'convergence'. Advice for the problem of nonconvergence will be demonstrated, based on the progressive lightening of the random effects structure (Singman & Kellen, 2017; for an alternative approach, especially with small samples, see Matuschek et al., 2017). At the end, on a different note, I will present a web application that facilitates data simulation for research and teaching (Bernabeu & Lynott, 2020).
Reproducibilidad en torno a una aplicación web
Las aplicaciones web nos ayudan a facilitar el uso de nuestro trabajo, ya que no requieren programación para utilizarlas. Crear estas aplicaciones en R, mediante paquetes como "shiny" o "flexdashboard", ofrece múltiples ventajas. Entre ellas destaca la reproducibilidad, tal como veremos en torno a una aplicación para la simulación de datos (https://github.com/pablobernabeu/Experimental-data-simulation).